人工智能 LLM 革命黎明:Copilot as a Service 将打造无数超级个体,核心能力是预测与自主 by 麦克船长

最近对于本轮生成式 AI 浪潮的讨论,进入了一个新阶段,大家从模糊地认为是巨大变革,逐渐开始探讨具体的变革机会点。我想讲讲自己对于本轮技术变革,在 to B 领域的一些基本观点。这些基本观点,是有争议的、非共识的,但我想有必要输出,以换来更多朋友与我的交流碰撞。
因此本文围绕本轮生成式 AI 在 To B 领域的应用落地,分五部分探讨:
- 数字化应用演进曲线(包括 To B 和 To C)
- 初步探讨 To B 领域当下用到的 AI 核心能力是什么
- 关于预测(Prediction)
- 关于自主(Autonomy)
- 什么样的团队会把握住这次机遇?最佳切入点是什么?
一、麦克船长:数字化应用演进曲线
为什么聊 to B 领域?当下阶段的生成式 AI 技术在 to C 和 to B 领域的应用差异是非常大的。理解这件事情,我们要宏观看下大时间尺度上,我们过去、当下、未来经历什么技术演进。陆奇博士提过将数字化应用的发展分为三个阶段 information → model → action,受此启发我在今年 4 月份时按照横轴是时间线、纵轴是 AI 能力发展、上是 to B、下是 to C 画了如下这张整体理解数字化应用的演进图:
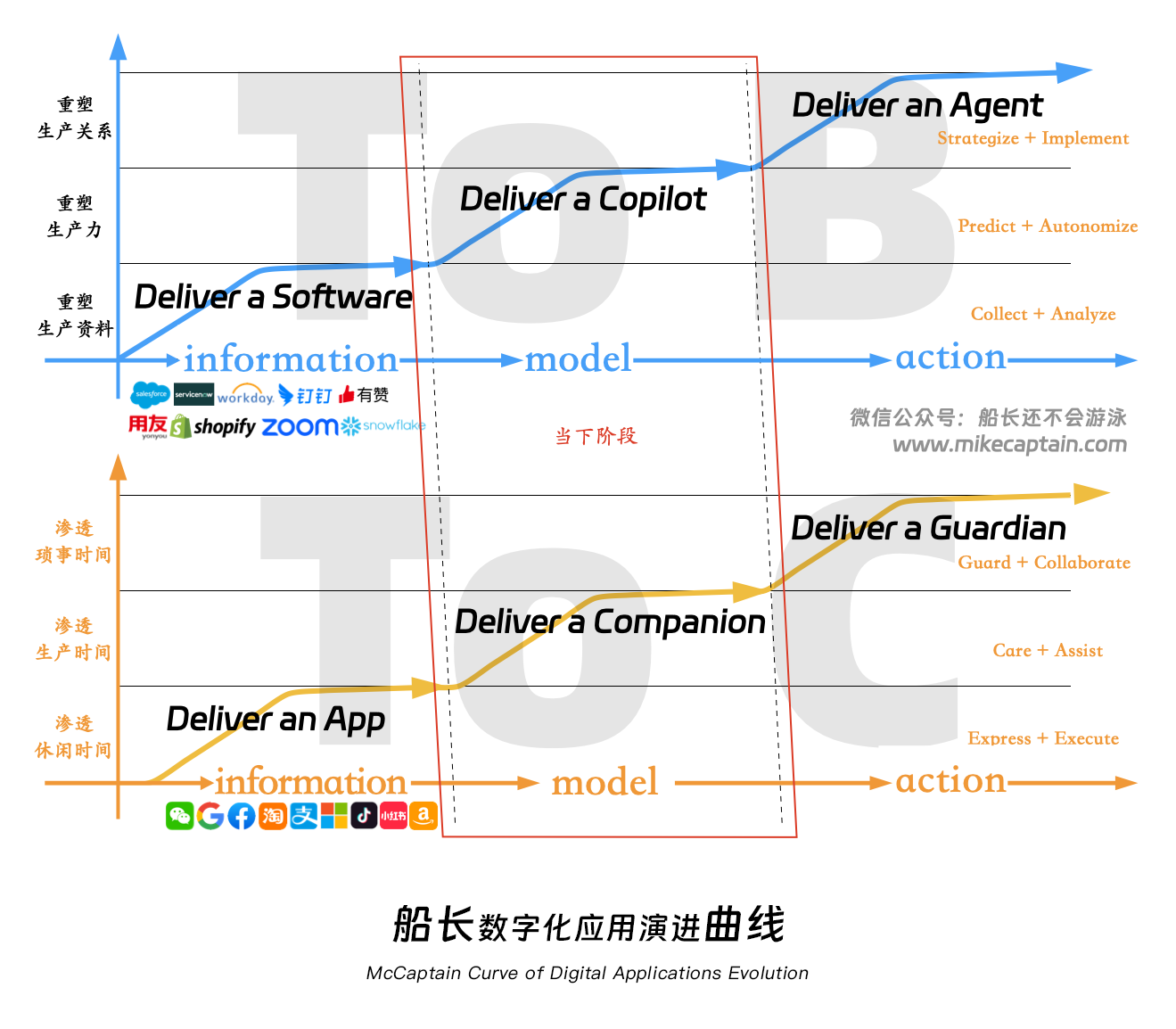
这张图我会在后续的文章中反复提起,也欢迎大家留言与我探讨,下面解释一下。
首先,我们把人类对于数字化应用的需求结构分为这三个阶段 information → model → action。在商业需求推动下,每个阶段 B 端发展都比 C 端应用早一大步。
第一阶段从 PC 诞生到 2022 年前后,数字化应用提供 information 价值,随计算设备、I/O 设备、三大网络(信息流/金流/物流)基础发展,在不同时期出现适配其时下人类预期的应用,向 B 端 Deliver Softwares(Collect + Analyze),向 C 端 Deliver Apps(Express + Execute)。这个阶段我们能看到 to B 一侧有 Salesforce、WorkDay、ServiceNow、Shopify、钉钉、有赞、用友等等应用,to C 一侧有 Google、Facebook、Twitter、Tik Tok、微信、淘宝、支付宝等等大量 killer app 出现。
当大模型智能涌现后,数字化应用进入第二阶段(从 2022 年前后开始),围绕 information → model 价值 B 端 Deliver Copilots(Predict + Autonomize)、C 端 Deliver Companions 提供关心的情绪价值以及帮助人类完成一些事情(Care + Assist)。当下最大机会是打造企业所需各行业 Copilot 搭档副手,而因目前模型精确性表现欠佳,但 C 端超越泛娱乐、进入深度使用时又要高精确性,因此当下并非挖掘 C 端商业价值最佳时机,可类比 PC 时代及最早期的互联网。这里展开的 to C 话题很多,我们以后再聊。
第三阶段是 information → model → action,即 AI 从能低延迟多模态 I/O,到对世界全息实时感知(超体)。此时 AI 与世界 I/O 全面对齐并逐步超越人类,B 端 Deliver Agents 为企业制定策略并实施(Strategize + Implement),像优秀的搭档;C 端 Deliver Guardians 忠诚守护、服务人类,并与人高效舒适地合作(Guard + Collaborate)。
数字化应用从仅能提供收集与分析,到可以成为人类的 AI 搭档,到对齐甚至超越人类后可以与人类重组生产关系,B 端沿着重塑生产要素发展,information 阶段重塑生产资料,model 阶段重塑生产力,action 阶段重塑生产关系。
根据 2019 年国家统计局对中国人日常使用时间的分布数据,休闲时间(自由活动)约 205 分钟,生产时间(工作学习)约 291 分钟,琐事时间(事务处理)约 193 分钟。数字化应用在 C 端沿着渗透用户时间发展,information 阶段渗透休闲时间,model 阶段渗透生产时间,action 阶段渗透琐事时间。
本文暂时不讨论 to C 的话题,我们围绕 to B 展开聊聊。
二、To B 领域:当下 AI 的核心能力是预测和自主
前段时间和一个做投资的朋友聊天时,聊到似乎生成式 AI 在中美 Startups 圈子的区别,是中国的公司都关注多模态,美国的公司都在关注 Autonomy(自主化,比如 Auto-GPT、BabyAGI、HuggingFace Transformers Agent 等)。我的体感上确实也如此,但并没有严格统计。那为什么是这两点呢?因为当下生成式 AI 的核心能力是预测和自主。

为什么中国对于关注多模态比较在意,我想可能是因为比较直观,似乎有肉眼可见的效果可以验证。但是对于 Autonomy,硅谷出现了大量开源项目释放给各行各业去推动商业自主化,而国内基本没有什么开源风气,国内 follow 开源风潮的开发者也大都是被美国的开源项目引领。因此出现的 Autonomy 方面的项目,也大多是基于拿来主义的二次开发。原本只是调用 GPT API、使用 LangChain 等开源工具这些项目就不被认为有商业价值,现在基于 API calling 实现的 agent 也都不是自己开发的,创投对此就更不感兴趣。但我认为中国的 Autonomy 机会在于产业空间巨大,原本数字化的链条越不深入,Autonomous AI 的空间就越大。
回到本文的话题上,为什么说当下生成式 AI 的核心能力是预测和自主呢?首先要明确,预测是指「预测使用者想要的内容」,自主是指「自主完成使用者的任务」。从完成任务的角度看,前者是「点」,后者是「线」,后者由前者组成。为了好理解,你可以把你想象成老板,AI 搭档就是你的员工,这个勤快、灵光的员工总是在想方设法预测老板想要 TA 交付的内容;更进一步地,这个员工还是管理岗具有培养价值的候选人,能够自主拆解任务、调用资源、按图索骥完成工作。
因此要注意这里的预测,不是预测明天的天气、预测未来股票的涨跌、预测后续俄乌战争的发展 …… 而「预测使用者想要的内容」并不是说使用者知道自己想要什么,而是使用者有能力判断是否使用 AI 预测的结果(即 AI 生成的内容)。相应地,如果使用者没有能力判断是否使用 AI 预测的结果,则 TA 不是目标用户。这也是为什么当下大多数普通用户在大多数场景里,不觉得现在的 AI 有用(ChatGPT 跨越 early adopter 和 early massive 之间的鸿沟也非常困难)。

当下国内看到的大多数 AI 项目都是在多模态维度上强化「预测」能力,相关的讨论较多,本文只小篇幅来让大家理解什么是预测。后文将重点聊下「自主」。
三、关于预测(Prediction)
首先看下从模型层面的理解。关于 LLM 的学习范式,可以看《麦克船长 LLM 革命 2:破晓》一文。如果您对 LLM 如何学习训练已经基本有概念的话,您一定知道目前基于 Transformer 架构的各种 LLM,甚至基于 ViT(Vision Transformer)的各种视觉模型,都是通过「预测」来实现生成的。这个预测,是大模型基于训练数据学习到的,在输入 prompt 的前提下最大概率对应的输出内容,是对于用户在给定输入内容情况下想要输出内容的预测。
再看下从应用层面的理解。如何理解预测?这里的预测,是指对目标用户认为所生成内容是否可用的预测(Predictions on the perceived usability of generated content for the target users)。反过来看,就是要求目标用户对于 TA 对生成内容具有判断力,也就是目标用户要自己在「判断」方面是这个领域的行家。例如 AI 生成的蒸汽朋克风格游戏素材,使用者不一定自己会画出这样的游戏素材,但是 TA 必须能够判断这个内容在应用场景里的可用性。如同一艘船长大多数时间里开船的是舵手,但是舵手要听船长的指挥。Gen-AI 以预测的方式生成内容的应用场景里,用户是 Pilot,AI 搭档只是 Copilot。

当下 AI 能力就是尽可能做好一个合格甚至优秀打工人,有人类为其兜底。所以才会演化出 Prompt Engineer(提示工程师)、Alignment Engineer(对齐工程师)等等操作优化 AI 的岗位。而未来对齐甚至超越人类的 Agent 阶段,AI 将会以 Strategize 能力替代 Predict 能力。
预测的技术拓展,要么是在某个模态上做到预测能力更强,要么是在新的模态上开发能力。模态远比大多数人想象的要广,不只是文本、图片、音频、视频,更具体地:
- 视频、图片、音乐、地图、3D、代码、手势、人声、动漫、动画、人像、游戏素材、虹膜指纹、面部表情、肢体语言,甚至各种物理量(速度/加速度、位置信息、光照、温湿度、重量)等等都是多模态研究的前沿领域,只是有些模态更关注识别与理解,有些模态更关注生成。
- 数字人,是典型的多模态领域探索的落地场景,是人声、人像、手势、面部表情、肢体语言等等多模态的集成。
- 数字场景,即将人置身于虚拟环境,这比较依赖 AR/VR/MR 设备的发展,当下 Vision Pro 的出现是一个契机。
- 创意设计策划,在所有需要人类灵感、脑暴作为源头的领域,AI 将成为灵感创意引擎,而且不仅仅是启发,可以直接产出半成品甚至成品方案。而因为产出方案的边际成本大幅降低,会反过来影响相关行业的经营流程被重塑,这是一个船长今后会深入与大家探讨的议题。
- 商用目的的图片生成,比如游戏、消费品、本地生活等领域。
- 商用目的的视频生成,比如电影、动漫、广告、教育、内容娱乐等领域。
- ……
围绕 Prediction 的探讨不作为本文重点,今后再探讨。
四、关于自主(Autonomy)
1、技术演进背景
2022 年 11 月底,基于 GPT-3.5 开发的 ChatGPT 应用,展现了与人类交流的强大能力。但是仍然存在几个重要的缺陷阻碍作为 Gen-AI 最先锋的模型走向 AGI:生成幻觉问题(hallucination)、知识截断问题(knowledge cutoff)。前者是准确性不足,后者是时效性不足。
其实这两个问题,在 2022 年 10 月 LangChain 发布时,就预示了解决方案(LLM + Retrieve),但是当时还未被生成式 AI 大规模采用,并且还没有消费级的 ChatBot 出现。到 2023 年 1 月时,LangChain 引起广泛重视,再到同年 3 月 ChatGPT 支持 plugins。无论是 LangChain 的方式还是 ChatGPT Plugins 的方式,都是实现通过插件的方式让大模型对互联网的最新数据进行检索再应用到大模型的功能。这样对 hallucination 和 knowledge cutoff 问题都有了较好的解法(虽然还未彻底解决)。
这样同时带来的另一个好处是,LLM 可以极大程度地接近人类使用在线工具链解决问题的过程。人类通过各类在线工具解决问题的过程,基本可以概括为检索、思考、生成、再检索、再思考、再生成 ……
3 月 16 日,数字游民 Gravitas 受到 @jacksonfall 和在 GPT-4 风险评估期间进行的测试的启发,发布了一个实验性的项目 EntreprenurGPT,并将其公开在 GitHub 上,希望用其测试 GPT-4 在商业环境中完成赚钱任务的可能性。Gravitas 给它启用了长期记忆来记住重要的事情以及让 AI 不要忘记自己的目标生意。自此 Gravitas 在其 Twitter 不断以文字直播的方式同步着 EntrepreneurGPT 的迭代进展。逐渐地,EntrepreneurGPT 还支持了 Google 检索、创建基于 GPT-4 的新对话(相当于在分裂自己)来完成分解的任务。
3 月 28 日,美国西雅图的中岛洋平(Yohei Nakajima)是 Untapped 风险投资的合伙人,他在其博客上发表了一篇文章《Task-driven Autonomous Agent Utilizing GPT-4, Pinecone, and LangChain for Diverse Applications》,并同步在其 twitter 上,很快引起大家的关注:
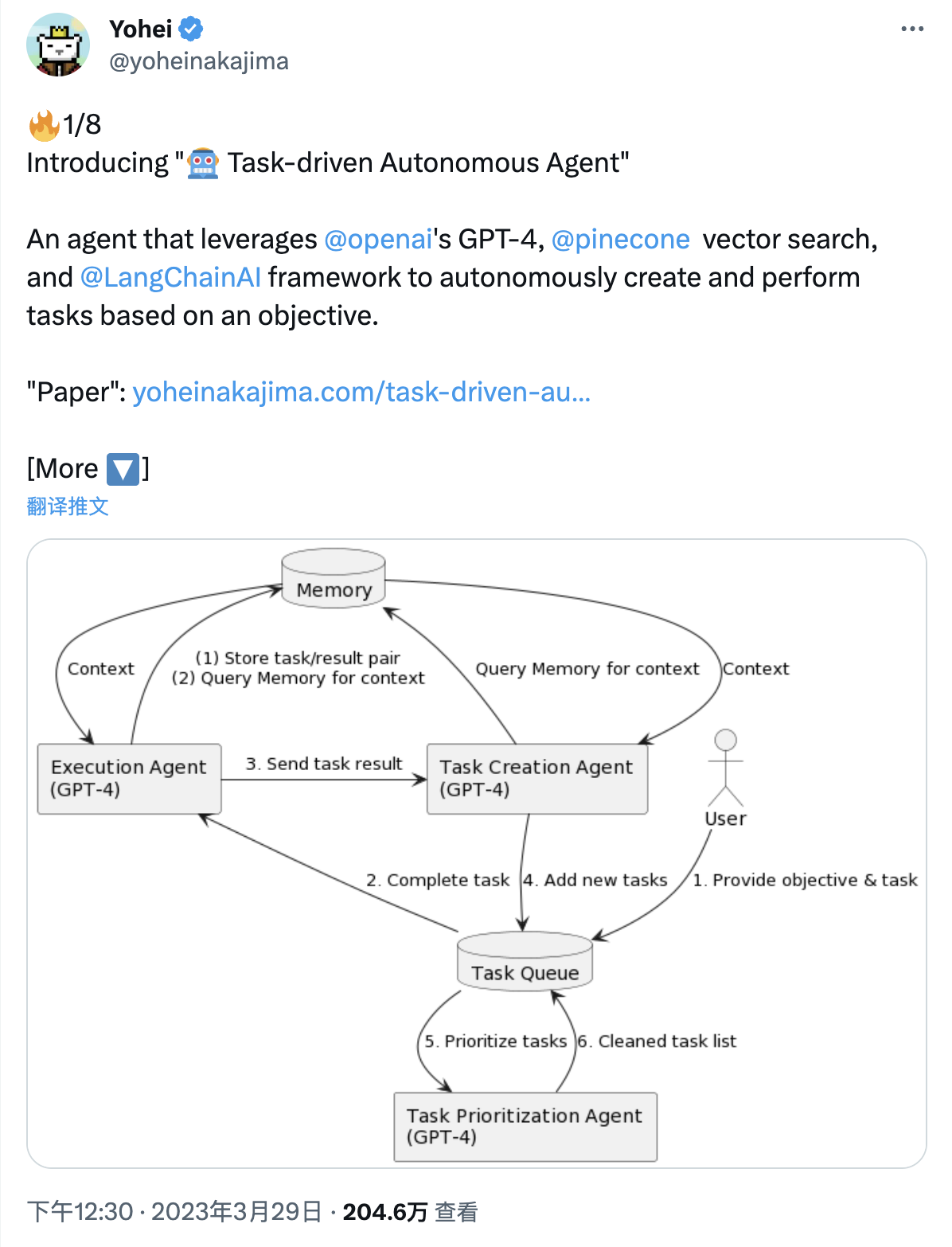
该文提到他们的研究中,提出了一种新颖的任务驱动自主 Agent,利用 OpenAI 的 GPT-4、Pinecone 向量搜索和 LangChain 框架,在各种领域执行各类泛化任务。该系统能够完成任务、基于完成的结果再生成新的任务,并实时优先处理任务。并且还讨论了潜在的未来改进,包括整合安全/安全代理、扩展功能、生成中期里程碑和整合实时优先更新。就像该论文的概要中所提到的,这项研究的意义在于展示了 AI 驱动的语言模型在各种约束和上下文中自主执行任务的潜力。
3 月 29 日,Gravitas 更名 EntrepreneurGPT 为 Auto-GPT,并加速迭代,添加信息提取、语音输入、运行程序代码等能力,于 4 月 3 日爬升至 GitHub Trending 第一名,项目地址如下:
- AutoGPT 项目地址:https://github.com/Significant-Gravitas/Auto-GPT
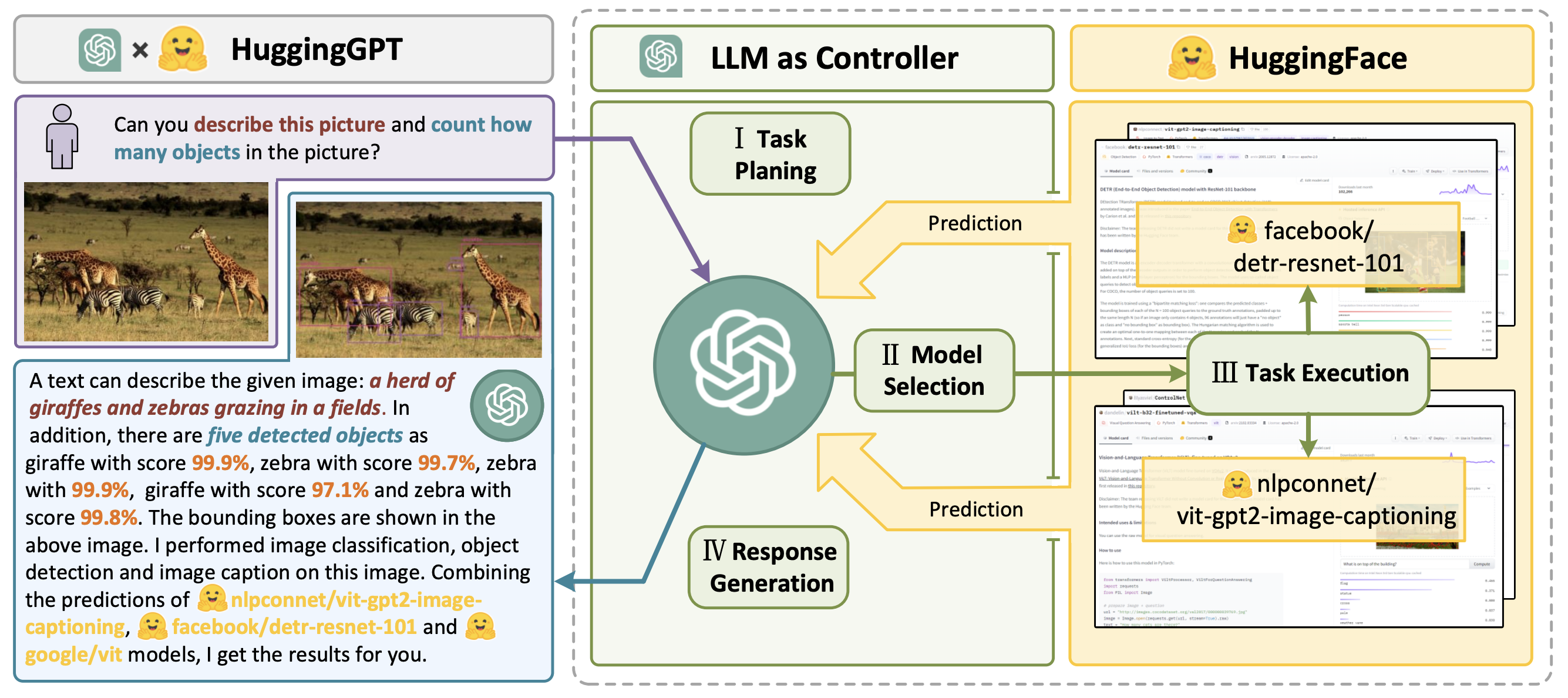
3 月 31 日,来自微软亚洲研究院(MSRA)与浙江大学(ZJU)组成的的研究团队发表了论文《HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace》,提出了一种新的方法,即用大语言模型(例如 ChatGPT、Claude 等)来控制现有的各种 AI 模型来解决更复杂的任务。

- HuggingGPT 项目地址:https://github.com/microsoft/JARVIS
- HuggingGPT 在线实例:https://huggingface.co/spaces/microsoft/HuggingGPT
- HuggingGPT 论文地址:https://arxiv.org/abs/2303.17580
具体地,HuggingGPT 可以利用 ChatGPT 来进行目标任务的拆解与规划,然后连接 HuggingFace 社区中的各种 AI 模型;根据社区中的各个模型的描述,来选型再执行所拆解出来的子任务;子任务的执行结果汇总后再给 ChatGPT 进行处理。
很快,在 4 月 3 日,Yohei Nakajima 在其 Twitter 宣布开源项目 Baby AGI,一个起初只有 105 行代码实现的「任务驱动的自动 Agent(Task-Driven Autonomous Agent)」,其项目地址如下:
- BabyAGI 项目地址:https://github.com/yoheinakajima/babyagi
4 月 7 日,Google 和 Stanford 的研究人员共同发布一篇论文《Generative Agents: Interactive Simulacra of Human Behavior》引起全球关注。在这篇论文提到的研究中,研究人员构建了一个虚拟小镇,镇内设有书店、咖啡厅、大学、公寓等设施,并有 25 个 AI 驱动的虚拟人生活其中。这 25 个 AI 都有其自己的生活、爱好、目标等等,彼此之间还可以交流、合作、记忆。
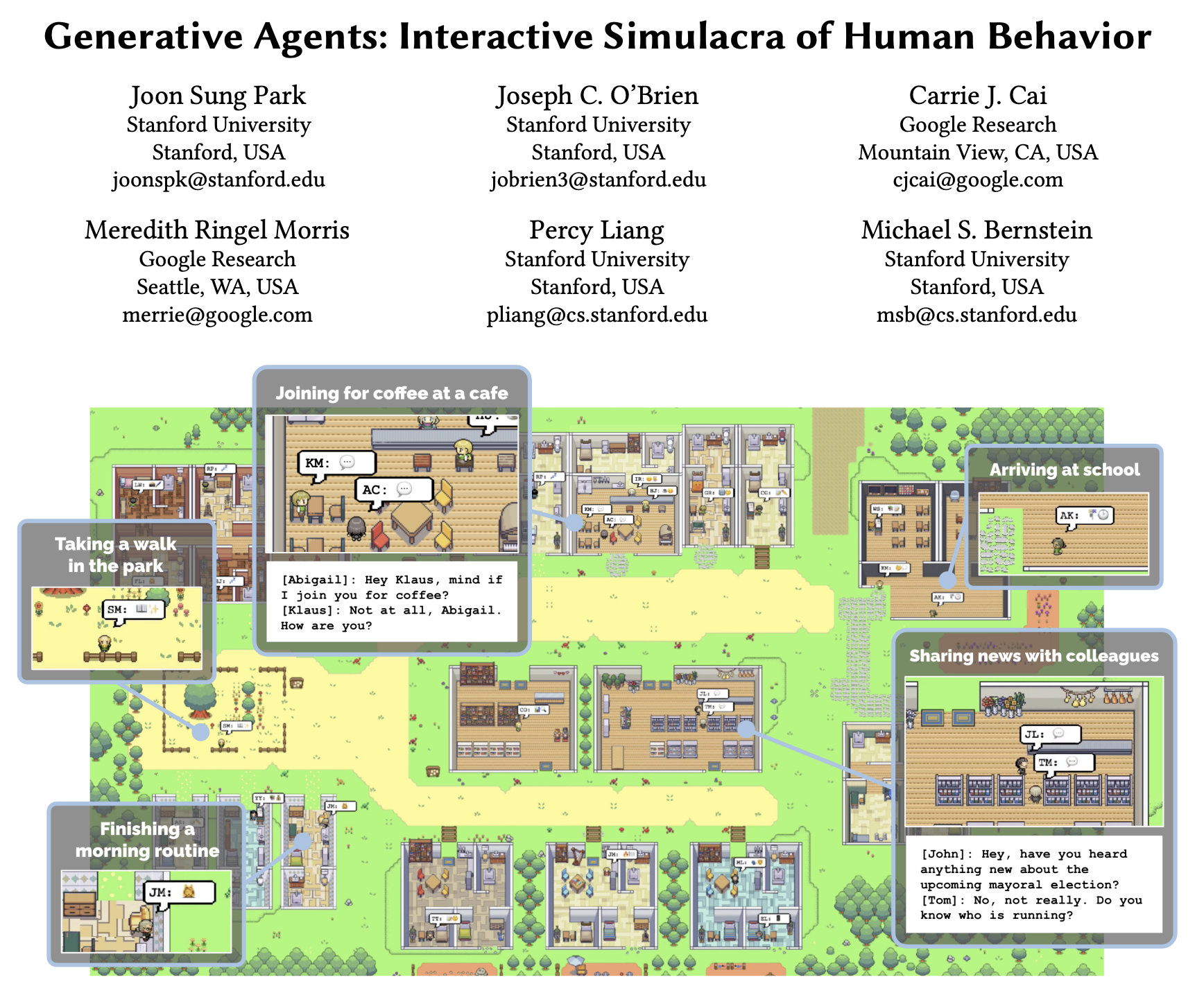
该研究引起全球轰动,人们开始讨论 AI 的自主意识、AI 的目标与人类的关系、AI 与 AI 的交互行为规范等等议题。还有很多人开始提到《西部世界》。
4 月 9 日,AgentGPT 发布,为 Auto-GPT 加上了 Web UI,使得其使用门槛进一步降低,并公开在 GitHub 上(https://github.com/reworkd/AgentGPT),AgentGPT 允许配置和部署自主的 AI 代理、定制 AI 名字、指定目标,然后 AgentGPT 会通过思考要完成的任务、执行它们并从结果中学习,试图实现目标。
5 月 11 日,HuggingFace 推出 API —— Transformers Agent,与 HuggingGPT 类似,Transformers Agent 连接 LLM 和 HuggingFace 社区里的各个模型,好似一个老板与一群员工组成了一个帮你完成任务的团队。可以在 https://huggingface.co/docs/transformers/transformers_agents 查看 Transformers Agent 的 API 文档。Transformers Agent 可以控制 HuggingFace 上 10 万多个模型,可以处理文本、图片、视频、音频、文档等,是一个多模态的 Agent。
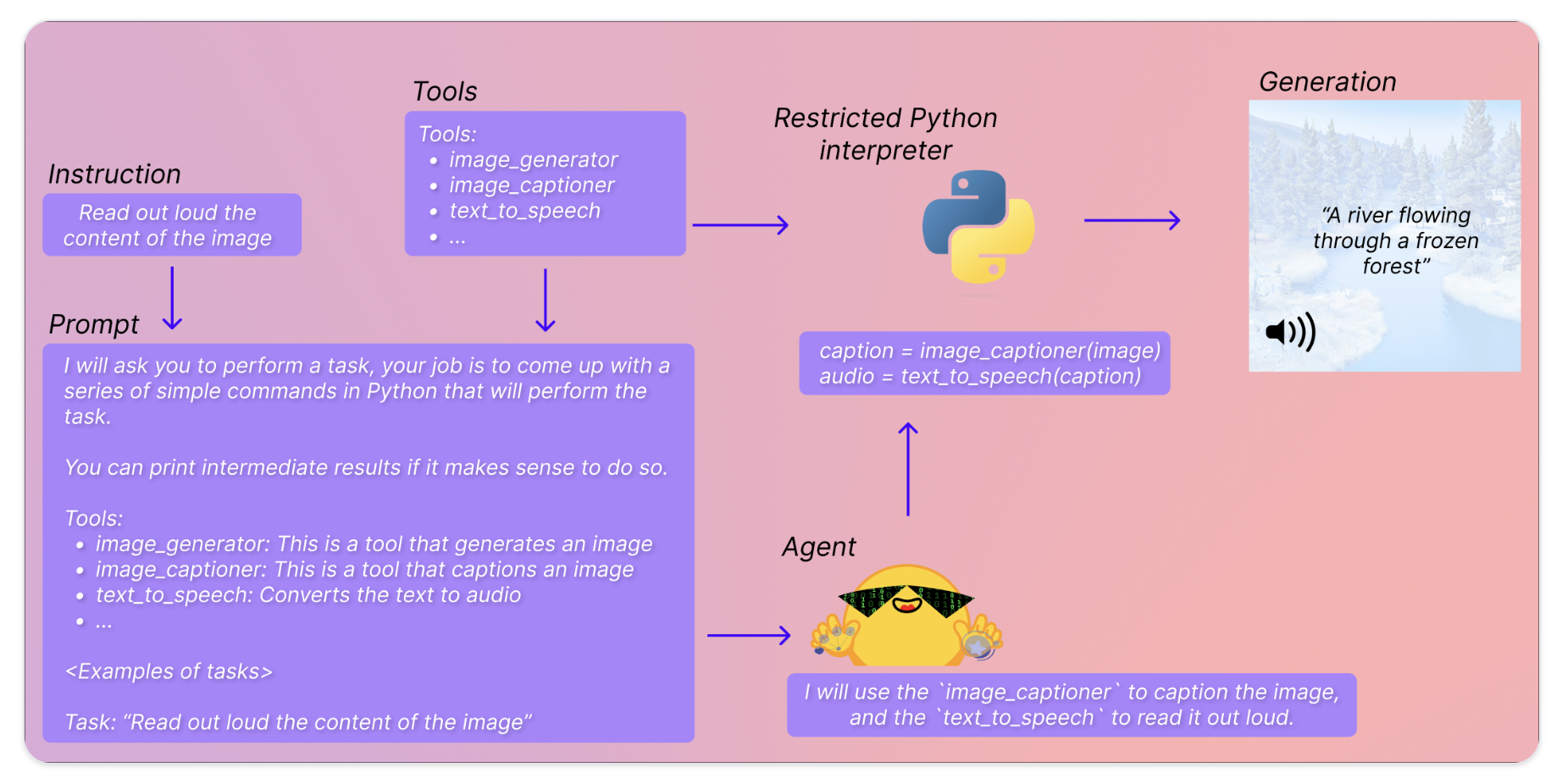
Transformers Agent 内置了多个组件,包括 Prompt、Tools、Agents、Python Interpreter(Python 语言解释器)。
……
这过程中还有无数 Autonomous AI 的项目出现,前沿研究在 AI 自主(Autonomy)方向极速狂奔。在 to B 领域,越自主(Autonomous)就意味着人类的管理颗粒度越粗,而人类在历次工业革命中被从工作与生活的脏累和琐碎中解脱出来,恰恰就是人类需要做的事情颗粒度越来越粗。比如 500 年前的人如果冬天想洗一个热水澡,则需要上山砍柴、背柴回家、劈柴、挑水、生火、烧水、兑水 …… 等等这么多环节以及对应的人力。但是现在的人们,只需要打开热水器的开关。
因此在当下 to B 场景里,我们可以思考的问题是,你想要做的领域里,如何打造这个领域的热水器?
2、商业自主化
在信息时代,数字化应用主要帮助我们做 Collect + Analyze,以电商经营为例:
- 生意参谋、蝉妈妈、多多参谋等产品,为电商商家,监控店铺流量、成交、访客等等数据并做一些分析。
- 打单软件帮商家集合淘宝、拼多多、京东、有赞、Amazon 等等各个平台的订单再交给打印设备,这是 Collect 的作用。
- 超级店长等店铺管理软件,提醒商家哪些商品库存不足、哪些订单物流异常等等。
- ……
所以每个小环节,都要有人来操作这些工具。每个工具都要和使用者之间构建一个交互通道,需要完整的产品抽象、UI 设计、功能设计等等。人与机器之间,在每个小环节上,都要进行彼此的 I/O(输入/输出)。因此一个软件是否好用、是否能把主次分清、合适展现什么信息 …… 等等考验一个产品经理的功底。而每个软件都要学会使用,考验了使用者的人力成本。

但是对于接触这些工具使用细节这件事,随着管理层级越向上的岗位,颗粒度越粗。如果 AI 扮演一个 Copilot 的角色就不一样了。当有了更多 AI 可以比 Auto-GPT 更强大地帮助人类一起拆解、优化、完成任务时,人类就可以在更高 level 的维度思考、管理、组织商业活动了。因此 BabyAGI 的作者中岛洋平(Yohei Nakajima)说「从自主智能体的发展趋势来看,每个人都有望成为一名经理」。
对于一个现代商业,通常需要具备如下三项资源,才能完成一个商业闭环开始着手赚钱:技术能力、获客能力、交付能力。而当下 AI 对于商业经营领域,在「自动化」这个命题下,最能帮助到的就是获客能力、交付能力。而我们要走向的,就是 AI 如何逐步能够完成复杂任务,让人类变成「甩手掌柜」。那么相比信息时代的产品,模型时代的产品就要「颗粒度变粗」。

我以内容制作为例。一个 UP 主的视频制作,过去的方法是,我们需要编写脚本创意、录制/采风/收集视频素材、字幕添加与校对、音轨编辑(BGM/音效等)、片头片尾制作、封面图制作、标题编写、多平台上传及信息填写、敏感词/违禁词修改、评论留言管理 …… 在这么繁杂的流程里,只要成本可接受,一般 UP 主都会走向雇佣至少一名助理的方式来处理上述大部分工作,仅仅留下脚本创意编写、基本素材生产的这两个环节,其他所有事务型处理全部解放。而当下模型时代,用户期待的正是如此,也就是用户越来越「像个老板」一样工作了。
类似地,各行各业都会有类似的事情发生,每个人都越来越像一个老板一样去工作,辅助 TA 的,你说是助理也好,Copilot 也好,总之就是用户/客户的一个搭档。因此在模型时代,比拼的是一个人的商机能力、判断能力、整合能力这 3 方面。商机能力一直是从古至今商业里的第一核心能力,判断力则是指能对 AI 搭档交付的结果进行定性或定量的评判(比如交付美术作品就需要审美的判断力等),整合能力就是把各项资源、人力、资金、技术等等组织好。
因此我们看到,在信息时代,每个环节都有相应的工具产品可以使用,但是每个环节人都要与机器进行 I/O,不仅人力成本高,而且对于每个环节的工具产品也都要求它有复杂、完备、精细打磨的人性化产品实现。所以一个信息时代里的工具产品刚问世时,最好聚焦到一个 I/O 环节里来做深,否则每个环节都做,就要做一大堆面向不同环节 I/O 的产品,对于创业公司来说相当于多个项目在并行,风险极大。
但是模型时代,我们需要在一个颗粒度相对粗的视角下,找到一个切入点,把某一段(而不是某个点)都让 AI 实现掉,让人类可以在商业运作方面升维。相应地,把握粗颗粒度下更关键的 I/O。
有人会问:信息时代的那些大产品,也不是一个「领域颗粒度细」的产品啊?比如钉钉里面,有聊天、日程、文档、邮件、组织管理 …… 钉钉说的五个在线几乎涵盖了在线办公的方方面面。再比如说 ERP 软件也是,里面包罗万象啥都有。但是我们会发现,信息时代的大产品,是众多「领域颗粒度细的产品」的集合体;而模型时代的大产品,是一个「领域颗粒度粗的产品」变得更粗。

3、自主(Autonomy)与自动(Automation)的区别
自动化,需要人类白盒化地显式定义好所有细节,再交给机器来复现。所有的程序都是自动化,因此我们听过「机器人流程自动化(Robot Process Automation)」、「证券交易自动化(Automated Securities Trading)」…… 而各种各样的编程,就是在把某个领域的工作自动化,这也是信息时代数字化应用的核心价值之一。
RPA 工具就是信息时代的「自动化」工具典型代表,而 RPA 产品渗透市场的最大难点,也恰恰就在于要显式地定义所有操作细节。因此我们能看到美国有大学已经开设了 RPA 课程,在用 RPA 的企业里要专门设置一个 RPA 运营岗位并进行为期不短的 RPA 使用培训,甚至因为过于需要「显式定义细节」以至于 RPA 软件公司还推出了速成 Python 脚本的课程。而 RPA 软件公司积累的所有代码,全部是为了显式地定义各种应用场景下 sentence by sentence 地敲出来的每一步操作模式。而这些在大模型面前,变得毫无价值,因为大模型在应用层具备的两大核心能力之一,就是根据目标任务拆解解决步骤、临时生成大量代码。

在模型时代,信息时代的「自动」是远远不够的。模型时代的机器是会「思考」的,机器正从「自动(Automation)」走向「自主(Autonomy)」。自主,是允许人类只需要简单地交代任务目标、约束条件和可用工具,就能让机器开始处理任务。这里人类被解放的生产力,是人类「显式定义细节」的工作量。机器自主化,将人类从显式定义细节的劳动中解放。
类似地,以前基于抢跑策略、各种技术分析的统计套利策略、基本面多因子模型等等构建的「显式定义细节」的量化交易模式,也会在大模型时代逐渐被干掉,而未来所衍生出来的黑盒化地交易策略很可能是无法被人类直观理解的。
4、如何过渡到自主化?
在一个具体场景中,如果原有的链路包括 20 个环节,曾经有 15 种工具产品在帮助解决其中 15 个环节的问题。那么每个环节如果投入可以 cover 成本,则可以存在一个创业公司的机会。或者「羊毛出在猪身上」的逻辑下,环节 A 不太挣钱,但是能帮助获客 or 提高访问频次(促活)or 刚需 …… 环节 B 可以赚钱,且 A 和 B 存在联动关系。比如一般在集市型的电商平台上开店是不花钱的,例如淘宝、亚马逊、拼多多,但是想大量获客,一般都需要广告投放。
而自主化,就是让用户更少的关注细节,提高经营维度。比如商家运营一个电商带货直播间,商家希望我只负责提供货的信息、直播投流预算,然后就等着处理订单就好了,中间的直播环节都不想碰,这时候商家可以去找一个 MCN 机构来解决,也可以找一个数字人解决方案公司来搞定。更进一步的,商家连货都不想管,最好 MCN 把选品也给我做了,甚至直播间的人设定位、粉丝运营、蓄水预告等等也都做了。
那么从哪个环节切入,来做一个自主化 AI 搭档呢?要从价值厚的环节切入,因为价值薄的环节,会被价值厚的环节吃掉,但反过来则不可能。

把「做价值厚的环节」和「模型时代产品的领域颗粒度要粗」结合起来,就要具体回答:哪个环节是价值厚的?围绕这个价值厚的环节,我们应该把哪些上下游也打包起来?
因此在「模型时代」创业的核心,是对于目标行业,要能犀利判断哪个环节是(对客户来说是)价值最厚的,然后切入。

而且这个价值最厚,还需要兼具可以形成数据飞轮的可能性,否则就会被通用大模型的泛化能力威胁到。因此,垂直领域 + 切入价值最厚环节 + 适当加粗领域颗粒度。而逐渐能够让颗粒度更粗、人类被更加解放,则需要循序渐进把握好这个颗粒度,这不是科学,而是与对目标客户的洞察有关。
五、谁会把握住?最佳切入点是什么?(To B 领域)
1、To B 领域生成式 AI 创业团队的五大能力维度要求
对一个垂直行业,能够在某个价值厚的单点的预测能力上深入,并能够用商业自主化的理念串联多个环节为一条线,是本次 Gen-AI 对 Startups 的技术壁垒、商业落地的要求。这通常需要相应团队具备如下 5+1 的能力:

- 深入垂直行业的 Know-How:非常了解过往服务目标客户的生态。
- 深入客户经营的 Know-How:非常了解客户是怎么做他的生意的。
- 相应行业的 to B 应用技术栈能力。
- 目标场景所需要的 AI 研发能力。
- 产品、技术、业务三者的整合能力。
- 可选能力:在信息时代参与过目标行业的数字化应用,踩过坑。
2、Copilot as a Service 在千行百业打造超级个体
在一个垂直领域,一旦 AI 应用能够切入价值最厚环节,能充当好 Pilot 角色的部分人类,就能在 Copilot 的加持下,伴随 AI 技术发展逐渐进化为「超级个体」。

而每一个能够帮助人类进化为超级个体的数字化应用,都有价值。但群雄逐鹿,最终走出来的一定是切入价值最厚环节,并伴随技术边界的拓展,不断发展能力边界(吃到技术红利)的数字化应用。
参考
https://www.mikecaptain.com/2023/04/19/eight-alls-for-understanding-and-shaping-the-ai-era/https://www.mikecaptain.com/2023/03/06/captain-aigc-2-llm/https://yoheinakajima.com/task-driven-autonomous-agent-utilizing-gpt-4-pinecone-and-langchain-for-diverse-applications/https://mp.weixin.qq.com/s/haf_mB2Fr0d2Xa3Ra2geyghttps://arxiv.org/abs/2304.03442https://www.mikecaptain.com/2023/03/24/chatgpt-plugin/https://github.com/Significant-Gravitas/Auto-GPThttps://github.com/reworkd/AgentGPThttps://arxiv.org/abs/2303.17580https://mp.weixin.qq.com/s/tjPEFApzdLjn2Y7iz8O77Ahttp://www.gov.cn/xinwen/2019-01/25/content_5361065.htmhttps://github.com/seanpixel/Teenage-AGIhttps://huggingface.co/docs/transformers/transformers_agentshttps://mp.weixin.qq.com/s/nHTXdzdDfPQ4Tv6rTIqDJghttps://github.com/Significant-Gravitas/Auto-GPT)https://github.com/microsoft/JARVIShttps://huggingface.co/spaces/microsoft/HuggingGPThttps://github.com/yoheinakajima/babyagihttps://www.forbes.com/sites/lanceeliot/2023/04/04/using-chatgpt-to-control-and-leverage-other-ai-apps-such-as-hugging-face-gets-you-hugginggpt-prompting-eyebrow-raising-by-ai-ethics-and-ai-law/?sh=788ad875a6f7