麦克船长解读 LIMA 的表面对齐假设:少量多样性、高质量数据即可实现更好的对齐

5 月 22 日 LeCun 发推 称:
LIMA: LLaMA 65B + 1000 supervised samples = {GPT4, Bard} level performance. From @MetaAI
这是来自 Meta AI、卡耐基梅隆大学、南加州大学和特拉维夫大学的研究人员近期发表的一篇论文,他们通过训练 LLaMA 的 650 亿参数版本得到的 LIMA(Less Is More for Alignment)来衡量这两个阶段的相对重要性,比较 LIMA 和其他模型(DaVinci003、BARD、Claude、GPT-4)的结果来评价模型表现,评价方式一是通过人工,二是通过 GPT-4。从结果来看,LIMA 展现了强大的性能。研究人员提出了「表面对齐假设(Superfacial Alignment Hypothesis)」,这些实验结果强烈地表明,大型语言模型中几乎所有的知识都是在预训练阶段学到的,只需要有限的指令微调数据,就可以教会模型产生高质量的输出。
一、大语言模型的两个训练阶段
麦克船长在 2023 年 3 月初的《人工智能 LLM 革命破晓:一文读懂当下超大语言模型发展现状》一文中提到过,当下大语言模型(Large Language Models,LLMs)的训练范式已经到了第三阶段。这个阶段的主要范式是「预训练-人工反馈强化学习-提示(Pre-train, RLHF and Prompt)」和「预训练-人工反馈强化学习-微调-提示(Pre-train, RLHF, Fine-tune and Prompt)」:
- 预训练-人工反馈强化学习-提示(Pre-train, RLHF and Prompt)学习范式:RLHF 方法最早由 OpenAI 在 2017 年论文《Deep reinforcement learning from human preferences》中提出,后来 GPT-2、GPT-3 相继发布后出现了虚假新闻、教唆犯罪、消极暗示等大量使用 GPT 系列的负面案例,于是 OpenAI 开始重视 Alignment 并最终在 2022 年上半年的 InstructGPT 上引入 RLHF 方法对齐人类道德伦理,起到很好的效果,后来这也被迭代回了 GPT-3 中以保障 API 调用时遵循人类道德伦理观念。这套范式也被用于大家熟悉的 ChatGPT 中,成为了目前的主流范式。
对于特定领域应用,也可以下游的 fine-tune,以期进一步提升效果,即如下范式:
- 预训练-人工反馈强化学习-微调-提示(Pre-train, RLHF, Fine-tune and Prompt)学习范式:预训练-人工反馈强化学习,都是上游阶段,微调和提示属于下游阶段。目前提供 fine-tune 的 GPT API 背后的 GPT 模型也是有 RLHF 的,已经不是最初没有考虑 alignment 的 GPT 版本了。
可以看到,目前大预言模型(LLM)的训练有两个阶段:预训练(Pre-train)和微调(Fine-tune):
- 预训练:从原始文本直接进行无监督训练。
- 微调:通过大规模指令微调(Instruction Tuning)和强化学习,更好地对齐下游任务和用户偏好。
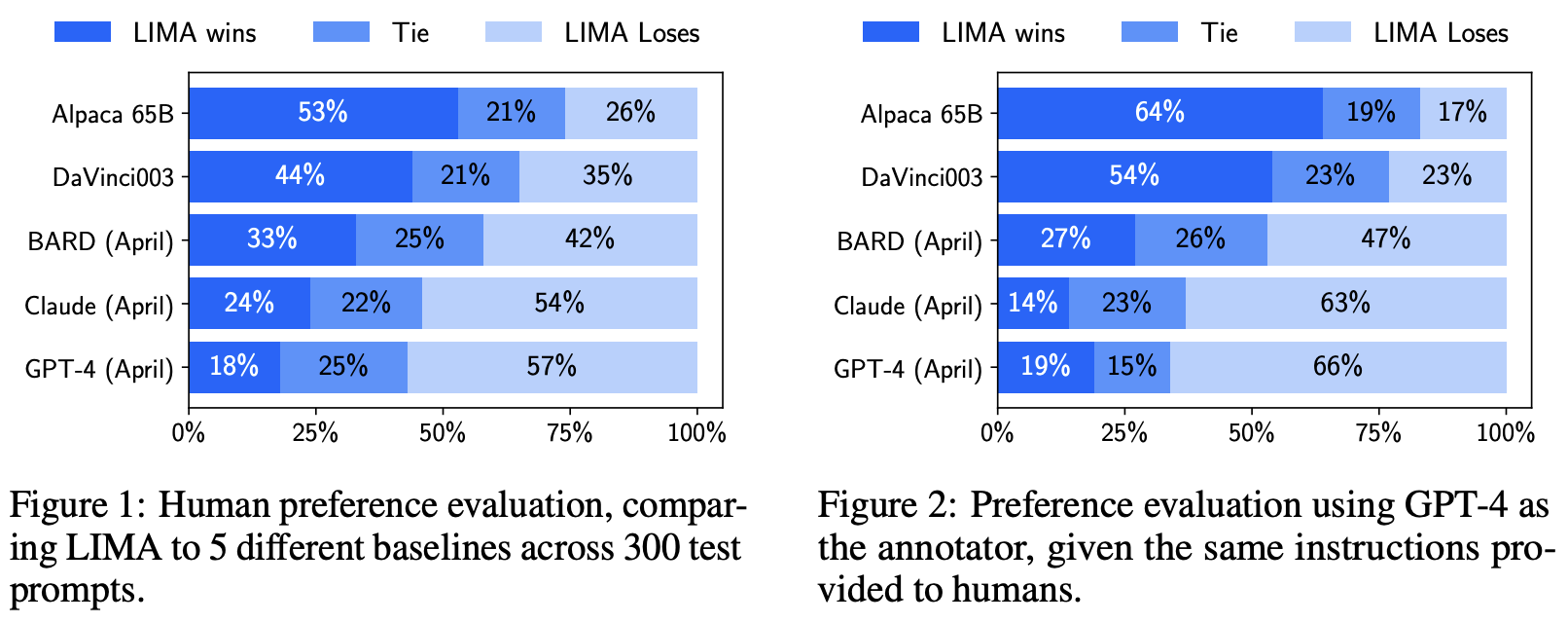
上图是 LIMA 与其他模型的对比实验结果,我们可以看到:用 1K 条数据微调 LLaMA-65B 得到的 LIMA,打败了用 52K 数据微调 LLaMA-65B 的 Alpaca(作者按照 Stanford 在 LLaMA-7B 上训练的方法自己微调了 LLaMA-65B 的版本);没有 RLHF(人工反馈强化学习,Reinforcement Learning with Human Feedback)的 LIMA 打败了有 RLHF 的 DaVinci003;不过 LIMA 性能还是显著不如 Google 的 BARD、Anthropic 的 Claude、OpenAI 的 Claude。但研究团队认为,这依然还是很具有突破性的发现,因为 LIMA 用了少得多的微调数据,以及没有 RLHF。
二、论文的关键内容
1、LIMA 的训练方法
LIMA 的训练方法主要包括以下步骤:
- 从预训练的大型语言模型(如 GPT-3 或 GPT-4)开始。
- 选择一组高质量的人工标注示例,这些示例包括用户提示和模型应该生成的理想响应。
- 使用这些示例对模型进行微调。
2、LIMA 所用的数据
下图是论文中给出的数据,文中提到的对预训练好的模型进行 Training 其实是我们一般所说的 Fine-tuning。
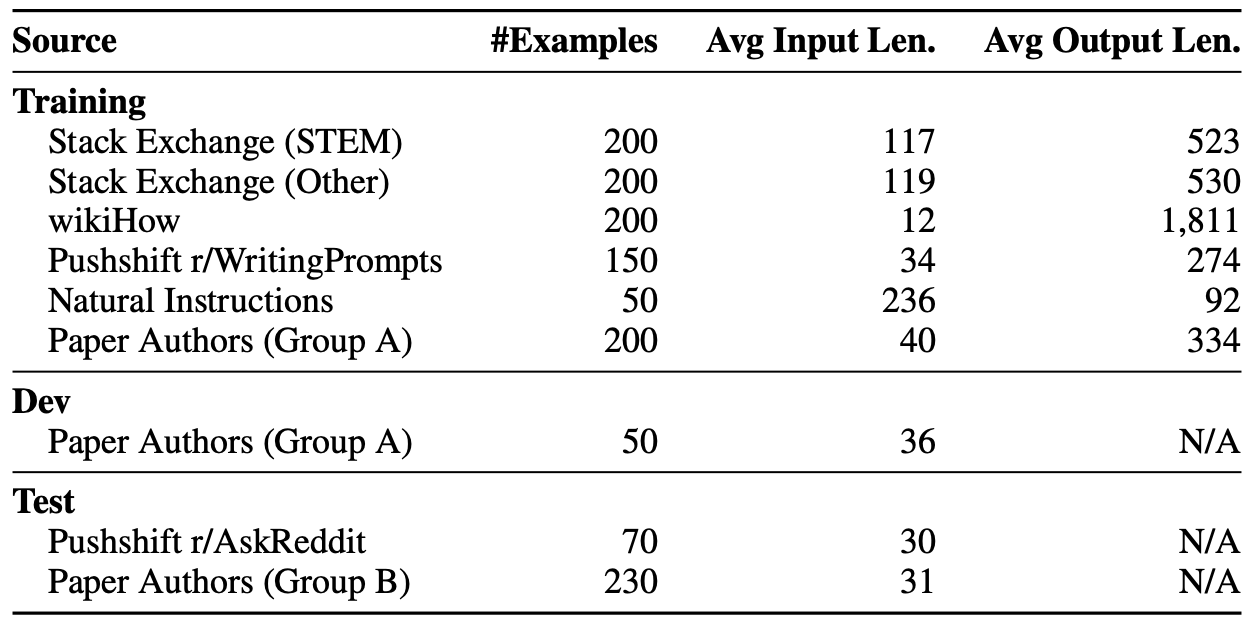
训练数据集(Training)
其中微调数据一共 1000 条,共约 75 万个 tokens,包括有 750 条来自各类数据源的数据(如下),以及 250 条来自作者自己编写的数据。
- 论文中将
Stack Exchange分为两类:STEM(科学、技术、工程和数学)和其他类别。 wikiHow是一个在线的 wiki,有超过 240,000 篇 how-to 文章,内容质量非常高。作者们从中采样了 19 个类别的共 200 篇文章。具体地,先采样 1 个类别,然后在该类别内采样 1 篇文章以确保多样性。作者们用标题作为 Prompt(比如「如何煎煮鸡蛋?」),用文章正文回应,用「The following answer …」替换「This article …」,并预处理了链接、图片和文本的某些部分,这些预处理和 prompt 改写方式可以作为我们日常处理数据方法的参考。Pushshift r/WritingPrompts是指从 Reddit 的WritingPrompts论坛收集的 150 个数据(问题和答案)。Natural Instructions数据来源于一篇名为《Super-Natural Instrctions: Generalization via Declarative Instructions on 1600+ NLP Tasks》的论文(Wang et al., 2022b)。这篇论文中的数据集包含了大量的自然语言生成任务,如摘要、改写和风格转换等。在这篇论文中,作者从「Super-Natural Instructions」数据集中选择了 50 个自然语言生成任务,并从每个任务中随机选择一个示例。这些示例稍微进行了一些编辑,以使其符合论文作者手动编写的 200 个示例的风格。尽管「Super-Natural Instructions」数据集中的任务的分布可能与潜在用户提示的分布不同,但作者直觉是这小部分样本增加了整体训练示例的多样性,可能会增加模型的鲁棒性。
开发数据集(Dev)
是用于在训练过程中调整模型参数的数据集。在这篇论文中,使用了 50 个作者提供的开发集数据。开发集数据都是用在训练过程中进行性能评估和微调,防止模型过拟合。这样可以在不触碰测试集的情况下,在训练过程中监控和调整性能。
测试数据集(Test)
论文中测试数据集由两部分组成:Pushshift r/AskReddit 和 Paper Authors (Group B),一共 300 个 prompts。
Pushshift r/AskReddit:包含了 70 个提示,来自 Reddit 社区下的主题论坛「AskReddit」。Paper Authors (Group B):包含了 230 个提示,由作者手动编写。
测试数据集的目的是评估模型的性能。
3、评估效果
作者们把 1000 组数据微调的 LLaMA-65B 和 OpenAI 的 DaVinci003、Stanford 基于 LLaMA-65B 用 52K 数据微调的 Alpaca、GPT-4、Anthropic 的 Claude、 Google 的 Bard 这些模型进行对比。在对比的情况下,GPT-4、Claude、Bard 领先的还是很明显的。但是在对 LIMA 进行的结果通过人类进行绝对评估(非相对比较的),发现 88% 的 LIMA 回应内容满足提示要求,50% 的回应内容被认为是优秀。
对于对话能力的评估,尽管 LIMA 在训练数据中没有对话示例,但作者们发现它能够进行连贯的多轮对话。并且,只需在训练集中添加 30 个手工制作的对话链,就可以显著提高这种能力。
4、消融实验:为什么可以做到 Less Is More for Alignment?
作者针对数据多样性、数据质量、数据量设计了消融实验(Ablations)。
- 数据多样性(Data Diversity):作者们比较了使用 Quality 过滤的 Stack Exchange 数据(具有 heterogeneous prompts、优秀的回应内容)和 wikiHow 数据(具有 homogeneous prompts、优秀的回应内容)进行训练的效果。结果显示,更多样化的数据产生了显著更高的性能。
- 数据质量(Data Quality):比较没有任何质量或风格过滤的 Stack Exchange 数据上训练的模型与在过滤后的数据集上训练的模型,结果显示差距显著。
- 数据量(Data Quantity):仅增加数据量而不增加提示的多样性,对模型的性能提升有限。
5、结论
作者提出了一个「表面对齐假设(Superfacial Alignment Hypothesis)」,即只需要少量精心挑选的示例就能实现对齐,而不需要大量的数据或复杂的方法。也就是说,即使只使用少量的训练数据,也能达到与使用大量数据的模型相当的性能。
参考
- https://twitter.com/ylecun
- https://arxiv.org/abs/2305.11206
- https://arxiv.org/abs/2204.07705