上船跑模型之 MacBook 上运行 Vicuna(ShareGPT 微调版 LLaMA-13B)
1、Vicuna 是什么?
一个基于 LLaMA 微调的大语言模型。Vicuna-13B 是一个使用 ShareGPT 收集的用户对话数据进行训练的开源 ChatBot。Vicuna 使用 GPT-4 进行评估,其在质量方面已经达到了超过 90% 的 OpenAI ChatGPT 和 Google Bard,同时在超过 90% 的情况下表现优于 LLaMA、Stanford Alpaca。
线上试用地址:https://chat.lmsys.org/
2、下载 FastChat
(fastchat) mikecaptain@CVN % git clone https://github.com/lm-sys/FastChat.git
(fastchat) mikecaptain@CVN % mv FastChat fastchat
(fastchat) mikecaptain@CVN % cd fastchat
我的设备是 MacBook Pro 14-inch(M2 Max, 64 GB RAM),所以在 macOS 上要安装下 rust 和 cmake:
(fastchat) mikecaptain@CVN % brew install rust cmake
安装包
(fastchat) mikecaptain@CVN % pip3 install --upgrade pip # enable PEP 660 support
(fastchat) mikecaptain@CVN % pip3 install -e .
3、下载 Vicuna delta weights
有 7B 和 13B 两个版本,其 Hugginface 主页分别为:
https://huggingface.co/lmsys/vicuna-7b-delta-v1.1https://huggingface.co/lmsys/vicuna-13b-delta-v1.1
追踪最新 delta 看如下页面:
https://github.com/lm-sys/FastChat/blob/main/docs/weights_version.md
下面以 13B 版本为例,先下载 lm-sys 提供的 delta weights:
(fastchat) mikecaptain@CVN % git clone https://huggingface.co/lmsys/vicuna-13b-delta-v1.1
(fastchat) mikecaptain@CVN % cd vicuna-13b-delta-v1
(fastchat) mikecaptain@CVN % wget -c https://huggingface.co/lmsys/vicuna-13b-delta-v1.1/resolve/main/pytorch_model-00001-of-00003.bin
(fastchat) mikecaptain@CVN % wget -c https://huggingface.co/lmsys/vicuna-13b-delta-v1.1/resolve/main/pytorch_model-00002-of-00003.bin
(fastchat) mikecaptain@CVN % wget -c https://huggingface.co/lmsys/vicuna-13b-delta-v1.1/resolve/main/pytorch_model-00003-of-00003.bin
4、将 LLaMA weights 转换为 HuggingFace 的格式
对于 LLaMA 原始的权重文件,在 HugginFace 官网文档里有这么一段话:
After downloading the weights, they will need to be converted to the Hugging Face Transformers format using the conversion script.
主要提到的「Hugging Face Transformers format」,所以这里就用到了官网给到的转换脚本文件(GitHub 网站上 huggingface 的 transformers 仓库里的「conver_llama_weights_to_hf.py」文件):
mikecaptain@CVN % wget https://raw.githubusercontent.com/huggingface/transformers/main/src/transformers/models/llama/convert_llama_weights_to_hf.py
然后调用转换脚本:
(fastchat) mikecaptain@CVN % python convert_llama_weights_to_hf.py --input_dir /path/to/downloaded/llama/weights --model_size 13B --output_dir /output/path
第一次转换失败,系统提示:
TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1. Downgrade the protobuf package to 3.20.x or lower.
2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
More information: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updates
查看一下本机的 protobuf 版本号,如果太高了就降低为 3.20:
(fastchat) mikecaptain@CVN llama % pip list | grep protobuf
protobuf 4.22.3
(fastchat) mikecaptain@CVN llama % conda install protobuf=3.20
再次运行,提示成功:
(fastchat) mikecaptain@CVN llama % python convert_llama_weights_to_hf.py --input_dir . --model_size 13B --output_dir .
Fetching all parameters from the checkpoint at ./13B.
Loading the checkpoint in a Llama model.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:09<00:00, 4.48it/s]
Saving in the Transformers format.
Saving a LlamaTokenizerFast to ..
在 output_dir 目录得到如下一组文件:
config.json
generation_config.json
pytorch_model-00001-of-00003.bin
pytorch_model-00002-of-00003.bin
pytorch_model-00003-of-00003.bin
pytorch_model.bin.index.json
special_tokens_map.json
tokenizer.json
tokenizer_config.json
5、根据 base、delta 一起生成 Vicuna 模型文件
如下是根据 base model、delta 一起生成 Vicuna 模型的命令,注意如果你这一步可能会执行很多次都不成功,船长会逐一带你解决问题。如果还是解决不了,建议你用在 Google 搜索错误信息时用双引号带上 "vicuna" 和 "fastchat" 进行搜索。
mikecaptain@CVN % python3 -m fastchat.model.apply_delta \
--base /path/to/llama-13b \
--target /output/path/to/vicuna-13b \
--delta lmsys/vicuna-13b-delta-v1.1
5.1、可能出现的「错误一」:FastChat 版本过低
如果出现如下类似提示,则需要升级 fschat 版本到 0.2.1 或以上(注意,本文编写时间为 2023 年 4 月初,请注意时效性)。
OSError: Can't load tokenizer for '/Users/mikecaptain/workspace/vicuna-13b-delta-v1.1'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local
directory with the same name. Otherwise, make sure '/Users/mikecaptain/workspace/vicuna-13b-delta-v1.1' is the correct path to a directory containing all relevant files for a LlamaTokenizer
tokenizer.
则查看 FastChat 的项目版本号:
(fastchat) mikecaptain@CVN fastchat % cat fschat.egg-info/PKG-INFO | grep Version
Metadata-Version: 2.1
Version: 0.1.9
其中 Version: 0.1.9 即代表 FastChat 版本号,升级 fschat 版本的方法如下:
(fastchat) mikecaptain@CVN % wget https://github.com/lm-sys/FastChat/archive/refs/tags/v0.2.1.tar.gz
(fastchat) mikecaptain@CVN % tar -xzvf FastChat-0.2.1.tar.gz
(fastchat) mikecaptain@CVN % mv FastChat-0.2.1 fastchat-0.2.1
(fastchat) mikecaptain@CVN % cd fastchat-0.2.1
(fastchat) mikecaptain@CVN % pip3 install -e .
再次查看版本就是正确的了:
(fastchat) mikecaptain@CVN fastchat-0.2.1 % pip list | grep fschat
fschat 0.2.1 /Users/mikecaptain/workspace/fastchat-0.2.1
5.2、可能出现的「错误二」:LLaMA 权重文件转换 HF 格式异常导致
再次执行 base、delta 合成 vicuna,如果提示 TypeError: not a string,则大概率是LLaMA 权重文件转换 HF 格式异常导致的,只需要重新转换一次即可。
再次执行:
mikecaptain@CVN % python3 -m fastchat.model.apply_delta \
--base /path/to/llama-13b \
--target /output/path/to/vicuna-13b \
--delta lmsys/vicuna-13b-delta-v1.1
得到如下结果:

终于成功合成 Vicuna 13B 的权重文件了。这里想提一下,只放出 delta 文件,也非常大,并没有节省文件大小,那为什么不把合成好的 Vicuna 直接放出来呢?因为 Meta 的 LLaMA 的使用协议所限,所以作者为了规避此问题,只放出了 delta,就没有关系了。
6、运行 Vicuna 13B
6.1、命令行模式
在搭载 Apple 芯片的 MacBook 上运行时,可以用如下命令:
(fastchat) mikecaptain@CVN % python3 -m fastchat.serve.cli --model-path /path/to/vicuna/weights --device mps --load-8bit

更多其他平台不同情况的运行方法,可以参考 https://github.com/lm-sys/FastChat#vicuna-weights。
6.2、Web GUI 模式
运行 Controller:
(fastchat) mikecaptain@CVN % python3 -m fastchat.serve.controller
运行 model worker:
(fastchat) mikecaptain@CVN % python3 -m fastchat.serve.model_worker --model-path /path/to/vicuna/weights --device mps --load-8bit
在 macOS 上如果你没有添加 --device mps 或 --device cpu 会出现提示错误:
AssertionError: Torch not compiled with CUDA enabled
然后运行 Gradio Web Server:
(fastchat) mikecaptain@CVN % python3 -m fastchat.serve.gradio_web_server
如果没有修改默认端口的话,则可以在浏览器访问 http://localhost:7861/,可以看到如下页面,就可以开始聊天啦:
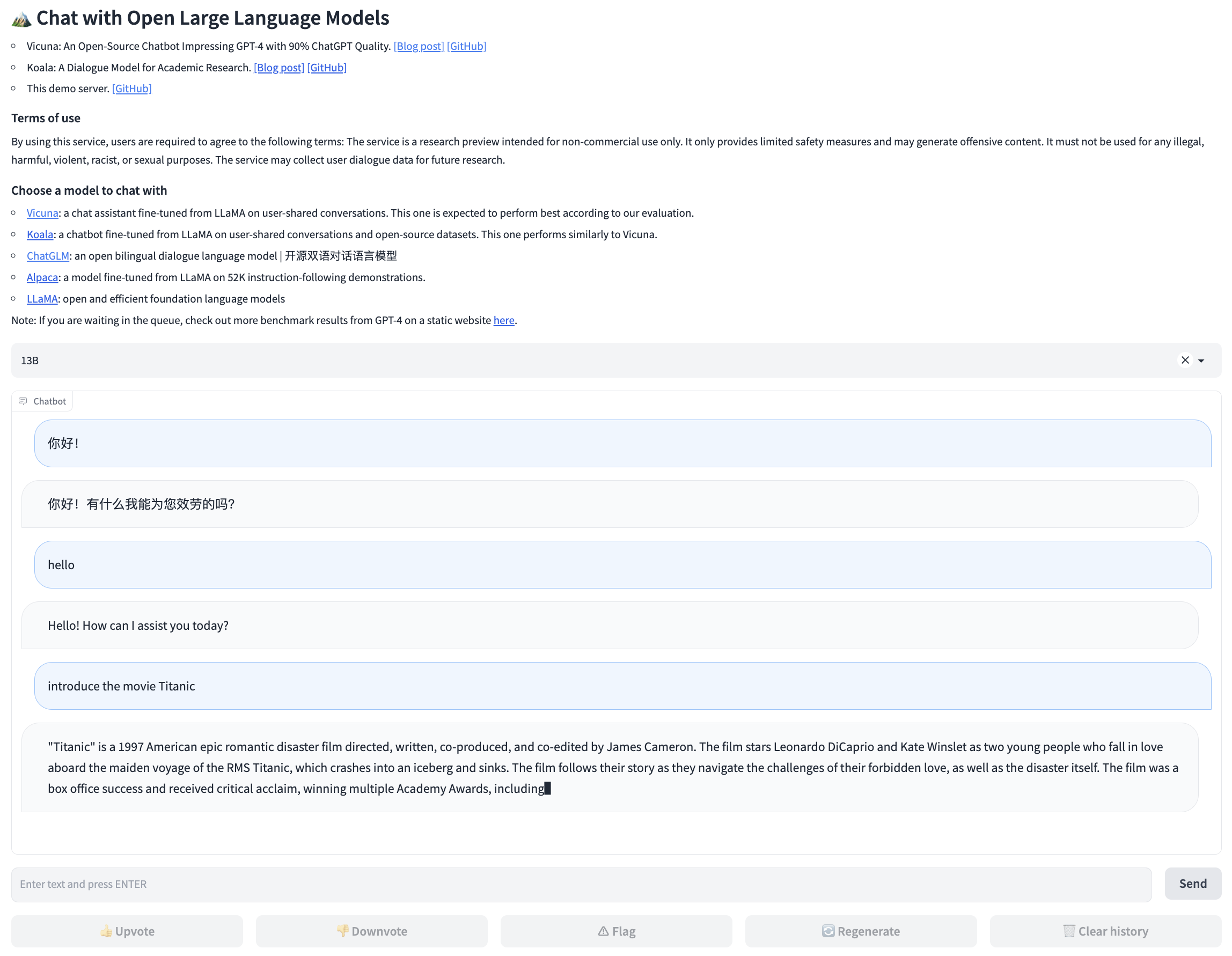
7、解释一下 Vicuna 13B 的配置文件
网络上还有很多其他版本的 vicuna-13b 模型权重文件,可以下载下来后,直接替换 pytorch_model-0000*-of-00003.bin 这一组文件,其他文件不要动。尤其是 tokenizer.model,如果不对是无法运行的。其他文件的配置大差不差。
7.1、config.json
"transformers_version"参数,我用的是与环境匹配一直的4.29.0.dev0。【!】"_name_or_path"参数。【!】
7.2、generation_config.json
- 其中也有
"transformers_version"参数,我将其与config.json文件保持一致。【!】
7.3、pytorch_model.bin.index.json
"metadata": {"total_size": 26031738880}【!】
7.4、tokenizer_config.json
- 需要有
"add_bos_token": true和"add_eos_token": false。不过没有也没关系。 - 不需要
special_tokens_map_file。不过有这个也没关系,哪怕写错了。
7.6、tokenizer.model、special_tokens_map.json
special_tokens_map.json没什么特别之处。tokenizer.model不太一样。【!】
参考
- https://github.com/lm-sys/FastChat#vicuna-weights
- https://github.com/lm-sys/FastChat/blob/main/docs/weights_version.md
- https://github.com/oobabooga/text-generation-webui/issues/122
- https://zhuanlan.zhihu.com/p/619551575
- https://github.com/lm-sys/FastChat/issues/411
- https://huggingface.co/docs/transformers/main/model_doc/llama