ChatGPT 插件的十大关注点:OpenAI 定义大模型消费级平台
北京时间 3 月 24 日凌晨,OpenAI 官方发布了重磅的「ChatGPT plugins」,这将开启大模型作为平台的模式定义、商业化模式定义、插件产品开发热潮、全新的大模型优化(LMO)等等。本文共分三个部分:
- 第一部分先速览几个重要的关注点,尤其是本次插件发布带来的行业影响;
- 第二部分针对本次 OpenAI 官方推出的插件做介绍;
- 第三部分是开发者最关心的第三方插件的支持能力做简述。
跟船长出发吧,坐稳了:
第一部分:速览 ChatGPT 插件,并聚焦本次变化带来的几大核心关注点
1、快速了解 ChatGPT 插件是什么
首先要知道 ChatGPT 插件是什么,我们来看下官方视频一睹为快:
以下这些公司产品已经接入 ChatGPT 插件:
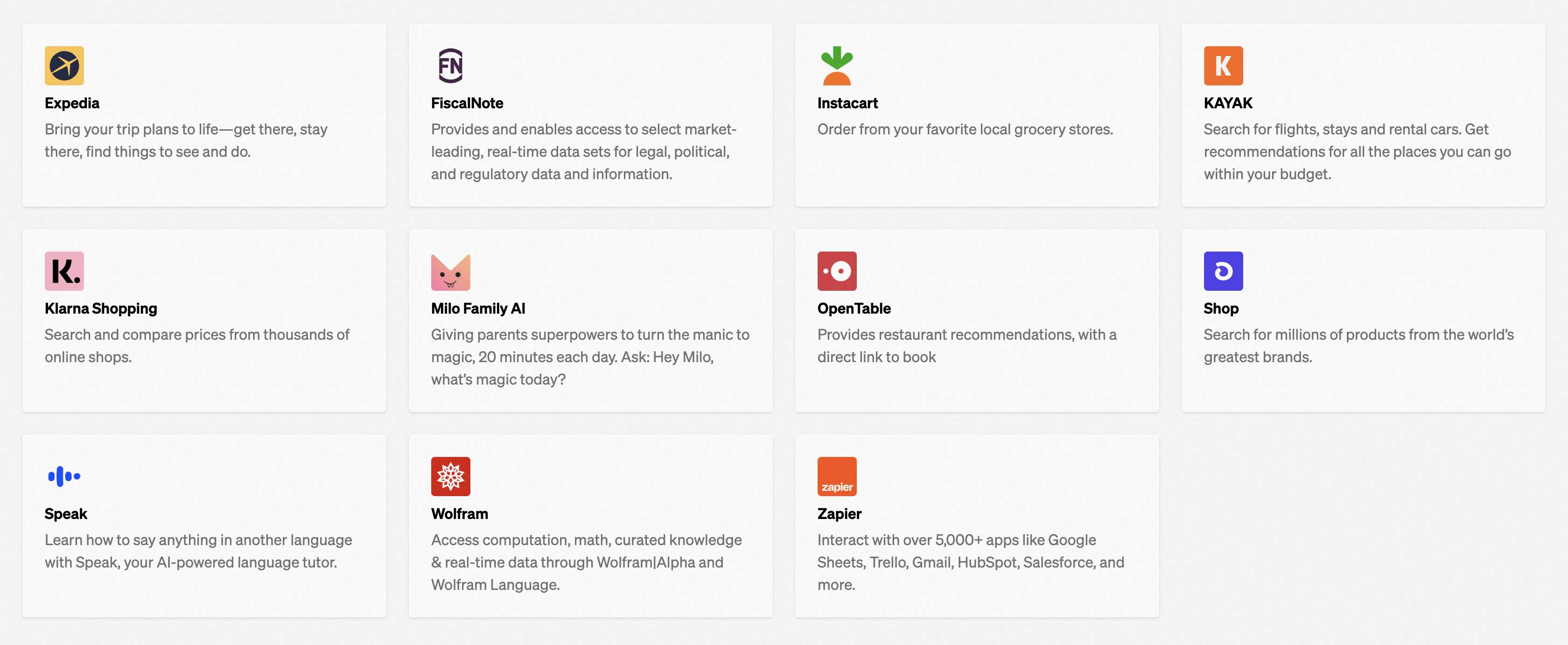
2、插件能做什么?
OpenAI 插件可以连接 ChatGPT 与第三方应用,通过接入你的应用做什么呢?举一些例子:
- 实时检索信息,例如足球赛事的实时比分情况、港股股票价格、最新资讯等。
- 检索知识库信息,例如针对你个的人电脑、针对公司的文档知识库等等,进行更智能地检索、调用、对话。
- 代替用户执行操作(船长一直说的对现实世界的「智能调度」):例如买机票酒旅、网购、订外卖等等。
目前 ChatGPT 的插件处于 limited alpha 阶段,需要申请加入 waitinglist(https://openai.com/waitlist/plugins)
3、ChatGPT 插件发布带来的行业重大变化(本文核心)
- 对话 + 插件:定义大模型的 to C 平台商业模式:此前大家一直认为大模型,或者当下更主要的大语言模型,其主要范式可能会成为个人助理,但是都在拭目以待 ChatGPT 的商业模式。本次 plugin 发布,已经展现了作为平台,如何连接开发者(通过插件连接),如何连接用户(通过对话连接)。这里的收费也变得很自然,开发者以插件方式接入大模型,并给平台相应的费用。
- 从 SEO 到 LMO:从 SEO(Search Engine Optimization,搜索引擎优化)到 LMO(Large Model Optimization),所有开发者为了获得大模型的流量,尤其是在红利期(用户流量远大于开发者供给)的阶段,都会开启 LMO 投入进行引流。而 ChatGPT 已经将「引流模式」定义好了。
- 支持 robots.txt:ChatGPT 的官方插件 Browsing 完全支持各个网站对于搜索引擎的 robots.txt 文件协议,各网站也可以针对 ChatGPT 进行优化,开启大模型引流时代。
- 定义「大模型-应用」的开放 API 标准:本次 ChatGPT 对于「大模型-应用」的 API 定义,将会成为行业的事实标准,各主动接入 ChatGPT 的应用,都会迎合该 API 定义,进而使得后续跟进的大模型,都将 follow ChatGPT 的标准定义。
- 未来应用内又可反向嵌入 ChatGPT,互通互联的大模型世界:当下主要还是基于 ChatGPT 到各应用的分发,OpenAI 未来几个月内,会允许开发者在自己的应用程序内继承 ChatGPT 插件,从而使用 ChatGPT 的能力,这样就有海量的应用可以为 OpenAI 带去数据价值、流量价值,及先进生产力提升时真实世界里其他产品上用户会如何使用。这样各个应用与 ChatGPT 的打通所产生的化学反应,就不止在 ChatGPT 内体验到了,其他各种产品也能让用户体验到。
- 大家期待的实时数据来了:通过插件接入其他应用,最直接解决的问题,就是数据不及时(之前 OpenAI 的自然语言模型,最新的数据也就是采用 2021 年 9 月之前的)。
- 知识更新问题被解决:分布式知识存储与更新维护:此前大家都会觉得大模型在某个时间切片上,将大量数据训练出一个大模型,后续如果知识更新了(比如大家喜欢举的例子:英国首相几个月换一个)大模型还是陈旧数据。ChatGPT 定义了插件范式,数据可以从第三方应用那里来,这将大家对于大模型的知识获取期待,转化为整个生态(大模型+应用)分布式维护知识体系。
- 很大程度解决「一本正经地胡说八道」的准确性问题:解决用户过渡依赖 ChatGPT 所产生的风险(之前 OpenAI 在 GPT-4 的 System Card 中探讨过),打通插件的数据后,用户有机会核对数据的准确性,应用也会及时更新。
- 应用价值还单薄吗?比原来好不少,船长此前经常说的「技术资产私有问题」这里可以小篇幅地探讨一下。在大模型处于封闭状态,无法对外引流时,大模型需要全知全能,就像一个可以解决任何问题的神。但是一旦它变成路由器,就不同了,它具备了「平台」的基本素质 —— 繁荣应用层所需的「技术资产私有」问题。但是目前只是从「流量模式」上解决了「技术资产私有价值」问题,从深度学习的角度,大模型依然有拿走应用层知识进而侵犯技术资产私有价值的风险,比如某天 ChatGPT 觉得某个大应用是个好生意,应该并入成为官方的第四个应用,但是 ChatGPT 有权限选择自己直接抄一个(扒光该应用的所有知识),而不是继续引流或者收购该应用,这对开发者是一个风险,而且大模型读取的深度越深,这种风险越大,因为换个角度这可以类比把内容直接暴露在搜索结果的搜索引擎,下游站点可能价值会被大幅削弱。
- 最基础的三大应用,已经被 OpenAI 官方做了:浏览插件、代码解释器、知识检索。这部分,大家看本文《ChatGPT plugins 发布:OpenAI 教你怎么做平台》第二部分就可以了。
目前第一批插件由如下这些产品所属的公司(当然看不到中国公司)创建,我们可以看到大家耳熟能详的在线旅游网站 Expedia、电商 SaaS 平台 Shopify 等等:
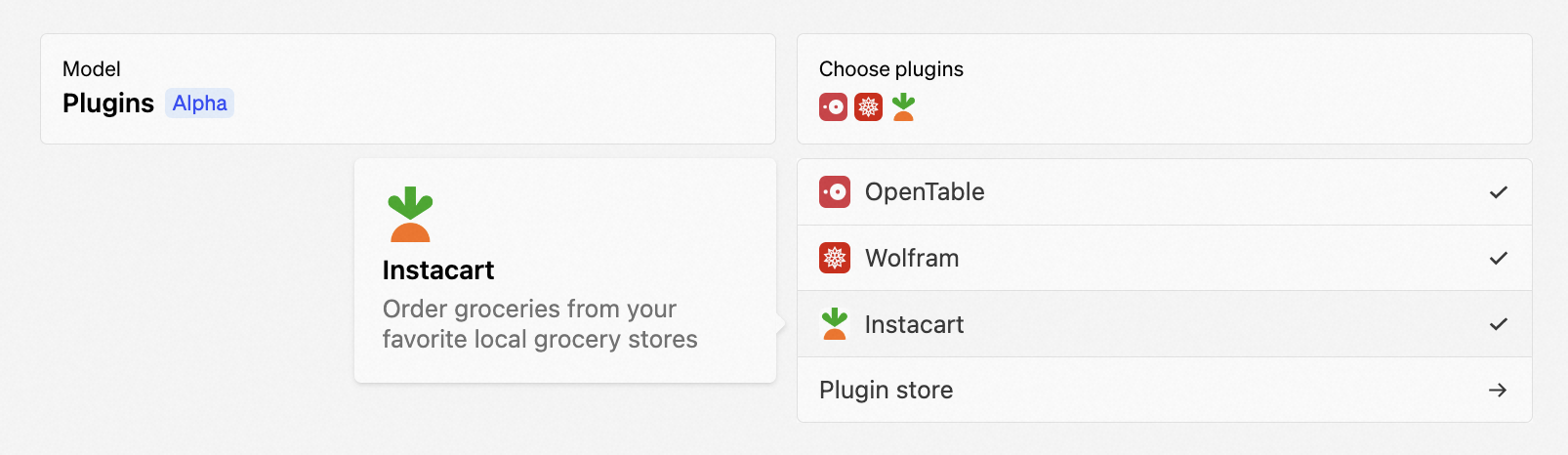
OpenAI 官方也搞了两个插件给大家试试手:浏览器(Web Browser)和代码解释器(Code Interpreter)。有了浏览器之后,大家一致诟病的数据不够新的问题就没有了。但是 Browser 是否出现,是交给 LLM 鹰嘴豆。
OpenAI 还开源了 ChatGPT Retrieval Plugin(https://github.com/openai/chatgpt-retrieval-plugin),这样就可以用开发者生态来帮助 ChatGPT 完成知识的时效更快、覆盖更高。我们在第二部分来逐一看下。
第二部分:官方三大插件(浏览插件、代码解释器、知识检索)
这三大插件是非常核心的三个基于 LLM 的功能,因此 OpenAI 官方直接做掉了,不给别人机会 —— 因为他们确实非常核心。
1、官方插件:Browsing(浏览器)
通过结合 OpenAI 在对齐(alignment)方面的研究(https://openai.com/blog/our-approach-to-alignment-research),以及大家一直希望解决的 ChatGPT 数据更新及时性的问题,推出了 Browsing 插件:
我们来看看 OpenAI 官方给出的视频介绍:
- ChatGPT 的 Browsing 插件,只会发出 get 请求,这样比较安全。但是该插件不会做提交表单等具有较大安全问题的操作。
- Browsing 插件使用微软 Bing 的搜索 API,因此具有:1)信息来源可靠性、真实性;2)相当于运行在浏览器的安全模式,阻止了不合适的内容。
- 从安全角度考虑,Browsing 插件独立运行,与 ChatGPT 的其他基础设施分开。
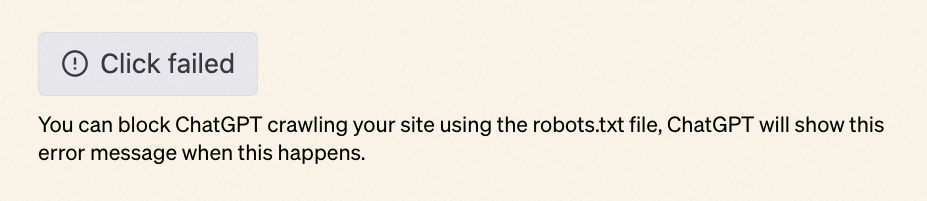
- ChatGPT 的 Browsing 插件作为浏览器读取网站信息时,User-Agent 字段设置的是 ChatGPT-User。因此任何网站如果想组织 ChatGPT Browsing 插件爬取内容,可以通过网站的 robots.txt 完全控制。ChatGPT Browsing 也完全遵守 robots.txt。当受限时,你会看到如下内容:
- ChatGPT Browsing 只会通过 ChatGPT-User 来获取网站信息,而不会用其他爬虫技术来获取。
- OpenAI 也发布了 IP 的出口范围。
- OpenAI 已经实施了速率限制措施,以避免向网站发送过多的流量。
- Browsing 插件会显示访问过的网站,并在 ChatGPT 的回复中引用来源。这样既能够回馈内容提供者,也能有助于信息的透明度。
- OpenAI 认为这是一种新的与网络互动的方式,因此希望收集所有使用者的各种反馈和意见,尤其是有关如何增加流量、提升信息来源的健康发展等方面的建议。
2、官方插件:Code Interpreter(代码解释器插件 Alpha 版),支持 Python
OpenAI 官方提供了一个环境隔离的的 Python 代码解释器,并且有临时的磁盘空间、对话中保持活跃(有上限时间控制)。解释器插件运行的代码会在一个持久会话中进行评估,该会话在聊天会话的持续时间内保持活动状态(具有上限超时),并且随后的调用可以在之前的基础上进行构建。支持将文件上传到当前的对话工作区,并下载结果。

该解释器所具备的编程能力,可以参阅论文《Evaluating Large Language Models Trained on Code》(https://arxiv.org/abs/2107.03374),大概相当于一个非常勤奋的初级程序员,和人类敲代码的速度差不多(但是不需要休息、思考迅速)。OpenAI 认为以下使用方向,用他们的代码解释器特别有用:
- 处理数学问题,包括定量、定性的问题。
- 数据分析和可视化。
- 文件不同格式的转换。
安全考虑,ChatGPT 连接 Code Interpreter 主要考虑问题,是运行环境的隔离,这样 AI 生成的代码就不会直接影响真实世界。主要包括三点:
- 严格的网络控制。
- 禁止生成的代码执行时访问外部互联网。
- 每个 session 都做了沙箱的资源限制。
3、官方插件:Retrieval(知识检索插件)
知识检索(Retrieval)插件使得 ChatGPT 在授权允许的情况下,通过自然语言的方式,就可以访问个人或组织的信息资源(如文件、emails 或公共文档等等)。
而且 Retrieval 插件完全开源,因此每个开发者都可以部署自己的插件版本,然后再注册到 ChatGPT。该插件利用 OpenAI Embeddings(https://platform.openai.com/docs/guides/embeddings)并支持开发者用矢量数据库(Milvus、Pinecone、Qdrant、Redis、Weaviate 或 Zilliz)来索引、搜索文档。信息资源(这些文档、emails 等)可以用 Webhooks 与数据库同步。
开源代码在这里 https://github.com/openai/chatgpt-retrieval-plugin。
安全考虑:知识检索插件搜索内容矢量数据库后,将最佳结果加到 ChatGPT 对话中,不使用任何其他外部内容,因此关于这个插件的主要风险就知识数据授权和隐私问题。这里就完全交由各个开发者来自行控制了,比如假设某酒店的系统接入了 ChatGPT 的知识检索插件,但是没有很好地尊重隐私,那么 ChatGPT 的对话结果中就会出现通过该酒店平台获取到的用户个人隐私信息,因此这其实是完全由知识检索插件使用者来自省决定的,与目前的互联网产品风险是一致的。
第三部分:开发者最关心的第三方插件(目前还是 Alpha 版)
1、速览
第三方插件由一个 manifest 的清单文件描述,详细内容可以查阅 https://platform.openai.com/docs/plugins/getting-started/writing-descriptions,如下:
{
"schema_version": "v1",
"name_for_human": "TODO Manager",
"name_for_model": "todo_manager",
"description_for_human": "Manages your TODOs!",
"description_for_model": "An app for managing a user's TODOs",
"api": { "url": "/openapi.json" },
"auth": { "type": "none" },
"logo_url": "https://example.com/logo.png",
"legal_info_url": "http://example.com",
"contact_email": "hello@example.com"
}
开发插件的步骤:
- 构建一个 API,包含你想要语言模型调用的端点(可以是新的API、现有API或专门设计用于LLM的现有API的包装器)。
- 创建一个 OpenAPI 规范文件,记录 API,以及一个包含一些插件特定元数据的清单文件,链接到OpenAPI规范文件。
在 chat.openai.com 上开始对话时,用户可以选择启用哪些第三方插件。已启用插件的文档会显示在对话上下文中,让模型能够在需要时调用适当的插件 API 来满足用户意图。目前,插件设计用于调用后端 API,但 OpenAI 也在探索能够调用客户端API的插件。
详细的开发第三方插件的流程,可以参考文档 https://platform.openai.com/docs/plugins/introduction,这里船长做个简单的流程介绍,大家可以关注我的公众账号,follow 后续更新。
2、插件流程
要构建插件,了解端到端流程很重要。
- 创建清单文件并将其托管在
yourdomain.com/.well-known/ai-plugin.json
- 该文件包括有关插件的元数据(名称、徽标等)、所需的身份验证详细信息(身份验证类型、OAuth URL 等)和要公开的端点的 OpenAPI 规范。
- 模型将看到 OpenAPI 描述字段,这些字段可用于为不同字段提供自然语言描述。
- OpenAI 建议在开始时只公开 1-2 个端点,并使用最少数量的参数,以最小化文本长度。插件说明、API 请求和 API 响应都插入到 ChatGPT 的对话中。这算作模型的上下文限制。
- 在 ChatGPT UI 中注册你的插件
- 从顶部下拉菜单中选择插件模型,然后选择「Plugins」、「Plugin Store」,最后选择「Install an unverified plugin」或「Develop your own plugin」。
- 如果需要身份验证,则提供 OAuth 2 客户端 ID 和客户端密钥或 API 密钥。
- 用户激活你的插件
- 用户必须在 ChatGPT UI 中手动激活你的插件,ChatGPT 不会默认使用你的插件。
- 在 alpha 版本中,插件开发人员将能够与其他 15 个用户共享他们的插件(目前仅其他开发人员可以安装未经验证的插件)。未来,OpenAI 将推出一种提交插件进行审核以向 ChatGPT 的所有用户公开展示的方法。
- 如果需要身份验证,用户将通过 OAuth 被重定向到你的插件;你还可以选择在此创建新帐户。
- 未来,OpenAI 希望构建功能,以帮助用户发现有用和流行的插件。
- 用户开始对话
- OpenAI 将在发送给 ChatGPT 的消息中注入你的插件的简洁描述,对终端用户不可见。这将包括插件描述、端点和示例。
- 当用户提出相关问题时,如果它似乎相关,模型可能会选择从你的插件调用 API;对于 POST 请求,OpenAI 要求开发人员构建一个用户确认流程。
- 模型将把 API 结果合并到其向用户的响应中。
- 模型可能会在其响应中包括从 API 调用返回的链接。这些将被显示为富预览(使用 OpenGraph 协议,其中 OpenAI 提取
site_name、title、description、image和url字段)。
目前,OpenAI 将在插件对话 head 中发送用户的所在国家、地区(例如,如果你在美国加利福尼亚州,那么 head 看起来就像 {"openai-subdivision-1-iso-code": "US-CA"})。对于进一步的数据源,用户必须通过同意屏幕选择加入。这对于购物、餐厅、天气等非常有用。你可以在 OpenAI 开发者使用条款中阅读更多信息。
结尾
更进一步对插件应用、插件开发的探讨,船长将放在后续的文章中,大家可以关注「船长还不会游泳」的公众账号获取第一时间的重大消息解读。
参考
https://openai.com/blog/chatgpt-pluginshttps://arxiv.org/abs/2107.03374https://platform.openai.com/docs/plugins/getting-startedhttps://github.com/openai/chatgpt-retrieval-pluginhttps://platform.openai.com/docs/plugins/introduction