开源 LLM 革命之 2:Stanford 研究团队发布基于 LLaMA 微调的 Alpaca 模型,仅花费不到 500 美元
本文目录
- 1、为什么做 Alpaca?
- 2、Self-Instruct
- 3、用的什么数据微调?
- 4、Alpaca 的算力开销及微调
- 5、Alpaca 性能评估
- 6、Alpaca 的局限性
- 7、Alpaca 带来的启发及优化空间
- 8、Alpaca.cpp 发布
- 参考
Meta 的 LLaMA 模型发布后不久,在 2023 年 3 月 13 日,一个叫 Alpaca 的模型被发布。Alpaca 是一个在 LLaMA-7B 基础上用 5.2 万条的「instruction-following」微调得到的 LLM,由 Stanford 大学的基础模型研究中心(Center for Research on Foundation Models,CRFM)团队发布,训练总花费约不到 600 美元。
为啥名字叫 Alpaca?LLaMA 是来自缩写(当然也是硬拗的),而 Alapaca 就纯粹是因为羊驼家族的名字了。作为羊驼家族的成员,llama 和 alpaca 都是来自南美。在南美有四类羊驼,分别是 llama(Lama glama)、alpaca(Vicugna pacos)、vicuña(Vicugna vicugna)、guanaco(或者叫 huanaco,Lama guanicoe)。从外形上,llama 和 alpaca 其实是长得有点像的,区别的方法一般是通过耳朵。耳朵比较长的,还有点弯弯的,是 llama;耳朵是直的,短一些的是 alpaca。值得一提的是,有人说秘鲁的国旗上有羊驼,其实秘鲁的国旗(下图左侧)是没有羊驼的,而秘鲁的政府旗、军旗上有的也不是羊驼,而是秘鲁的国宝 —— 骆马(vicuña)。

OK,不扯远了,如何分别各种草泥马的事情,还是交给搞动物学的朋友们,我们继续聊人工智能。Stanford CRFM 团队在其官方主页上发布了相关文章介绍 Alpaca,官方的一些相关参考资料如下:
- Blog:《Alpaca: A Strong, Replicable Instruction-Following Model》
- DEMO:https://crfm.stanford.edu/alpaca/
- Code:GitHub - Stanford Alpaca
1、为什么做 Alpaca?
尽管像 ChatGPT、Claude、New Bing 的 Chatbot 这些已经很厉害了,但是 CRFM 团队认为这些模型依然存在许多不足之处,尤其是它们可能生成虚假信息、传播社会刻板印象、产生有害语言等等。为了在这方面的研究上取得一些推进,学术界的参与至关重要。但不幸的是,在学术界进行关于指令跟随模型的研究一直很困难,因为没有一个容易获取且能够与 GPT-3.5 等闭源模型相媲美的模型。
刚好 Meta 发布了 LLaMA,CRFM 团队就基于 LLaMA-7B 微调了除了 Alpaca。
那么用什么数据来微调呢?我们先要介绍一下 Self-Instruct 再来聊 Alpaca,而且 Self-Instruct 才是重点。
2、Self-Instruct
2022 年 12 月底,在 ChatGPT 发布后不到一个月,Yizhong Wang 等几位学者共同发布了论文《SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions》。这篇论文主要是指出「可以用现成的、强大的大语言模型,来自动生成微调所需要的数据」,这样的好处,是大量地省去了人工编写 Instruction-Following 数据的工作量,因为这种数据通常在数量、多样性和创造性方面受到人工编写规模的限制,很难搞出非常多,这也就间接地限制了继续推进 LLM 的泛化能力拓展。这篇论文的作者引入 Self-Instruct,是一个用 LLM 来造数据用于微调的框架。整个流程从 LLM 生成指令、输入和输出样本,然后在使用它们对目标模型进行 finetune 之前,过滤无效或相似的样本。
论文作者将这个方法应用于原始的 GPT-3,性能测试结果显示在 Super-NaturalInstructions 任务上相对于原始模型实现了 33% 的绝对改进,与使用私有的用户数据和人工注释进行训练的 InstructGPT-001 的性能相当。为了进一步评估,论文作者还搞了一组专家编写的用于新任务的指令,并通过人工评估,结果显示使用 Self-Instruct 对 GPT-3 进行调优明显优于使用现有的公共指令数据集,而且作者自称是运用 Self-Instruct 框架的结果仅与 InstructGPT-001 相差 5% 的绝对差距。Self-Instruct 提供了一种几乎无需人工标注的方法,可以使预训练语言模型与指令对齐。
该篇论文的研究团队还公开了他们的合成数据集 https://github.com/yizhongw/self-instruct(截止本文编写时,GitHub 上已有 2.5K 的 stars 了)。
2.1、数据集的生成
这里讲的还是太粗糙了,我们根据 Self-Instruct 论文里的介绍可以看到是如下流程:
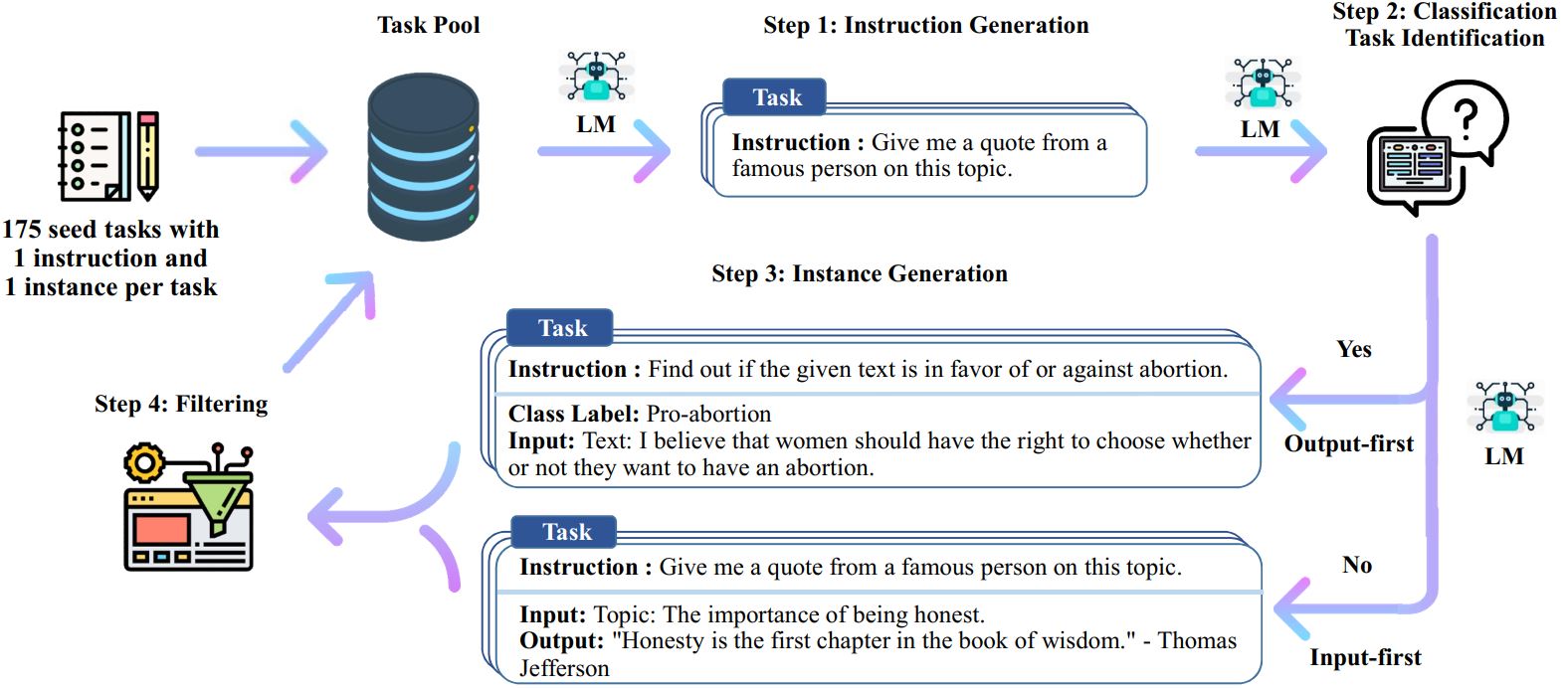
这里可以分为基本的四个步骤。
首先,CRFM 团队使用种子集作为提示,让 OpenAI 的 text-davinci-003 生成指令。
启次,来判断是否这个任务是一个分类任务。这里判断使用语言模型来实现的,而不是人工判断。
第三步,生成 instances,根据是否是分类任务,分为两类。分类也是用语言模型实现的,而不是人工判断。
- 如果是分类任务,则包括 instruction、input、output(即 class label)三部分,则先生成 output(即 class label),即 output-first。比如的判断一个句子是否有语法错误时,最好是让 AI 生成一个有语法错误的 output。
- 如果不是分类任务,则包括 instruction、input、output 三部分,则先生成 input,即 input-first。
比如以下这个属于分类任务,所以要 output-first:
Given the classification task definition and the class labels, generate an input that
corresponds to each of the class labels. If the task doesn’t require input, just generate the
correct class label.
Task: Classify the sentiment of the sentence into positive, negative, or mixed.
Output(Class label): mixed
Input(Sentence): I enjoy the flavor of the restaurant but their service is too slow.
Output(Class label): Positive
Input(Sentence): I had a great day today. The weather was beautiful and I spent time with friends.
Output(Class label): Negative
Input(Sentence): I was really disappointed by the latest superhero movie. I would not recommend it.
以下则不是一个分类任务,所以要 input-first:
Instruction: Given an address and city, come up
with the zip code.
Input:
Address: 123 Main Street, City: San Francisco
Output: 94105
CRFM 团队使用 self-instruct 种子集中的 175 个人工编写的「instruction-following」输出对。CRFM 团队还放出了这 175 个种子数据(https://github.com/yizhongw/self-instruct/blob/main/data/seed_tasks.jsonl),大家可以浏览下大致格式,与上面船长说的也是对应的:
{
"id": "seed_task_0",
"name": "breakfast_suggestion",
"instruction": "Is there anything I can eat for a breakfast that doesn't include eggs, yet includes protein, and has roughly 700-1000 calories?",
"instances":
[
{
"input": "",
"output": "Yes, you can have 1 oatmeal banana protein shake and 4 strips of bacon. The oatmeal banana protein shake may contain 1/2 cup oatmeal, 60 grams whey protein powder, 1/2 medium banana, 1tbsp flaxseed oil and 1/2 cup watter, totalling about 550 calories. The 4 strips of bacon contains about 200 calories."
}
],
"is_classification": false
}
最后一步,对于生成的结果,经过数据过滤再放到任务池(Task Pool)里。
2.2、数据集的多样性
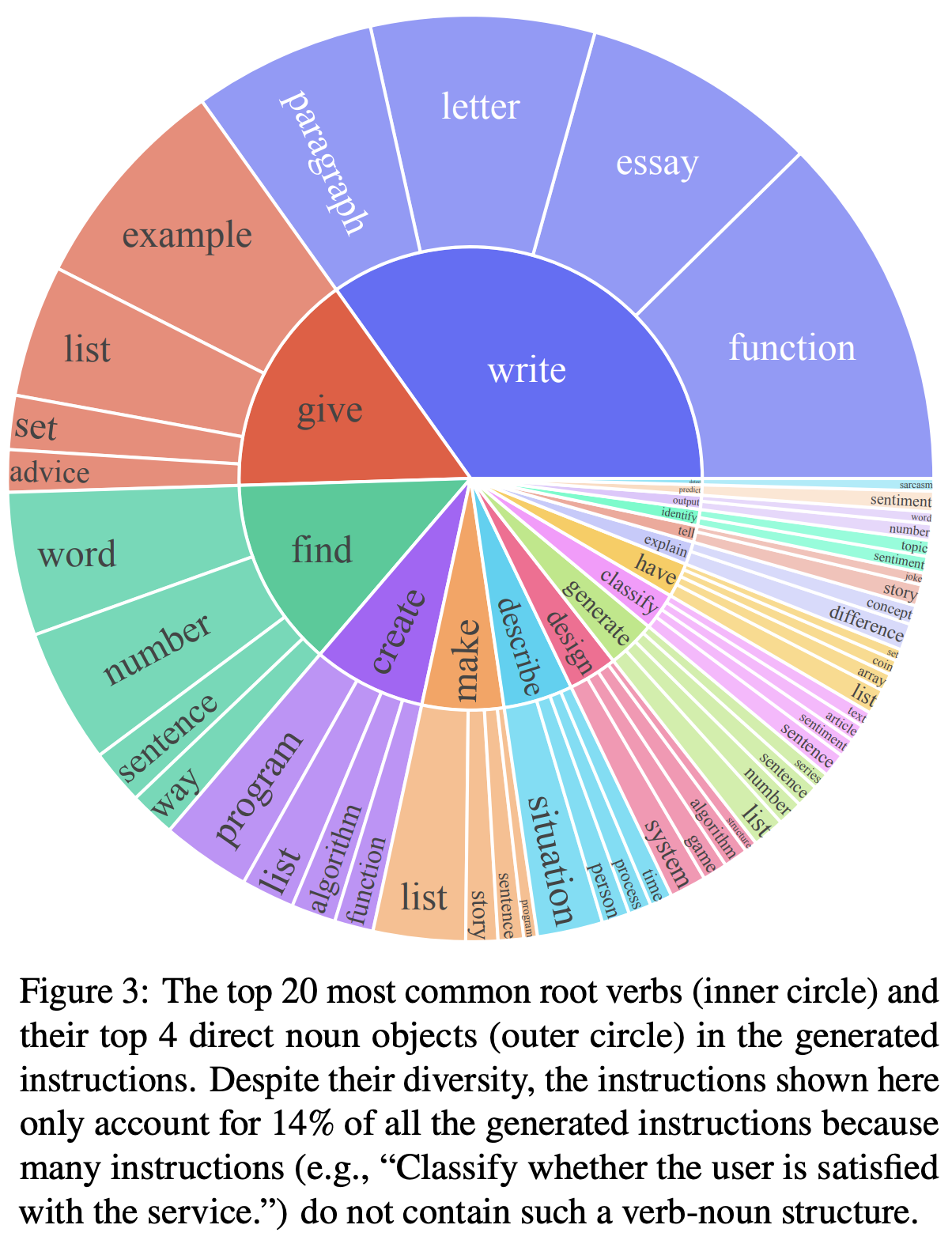
这些数据的分布多样性如下(下图内圈是动词,外圈是这个动词所作用在的名次,两者组合就能看出这是一个什么任务):
2.3、数据集的有效性
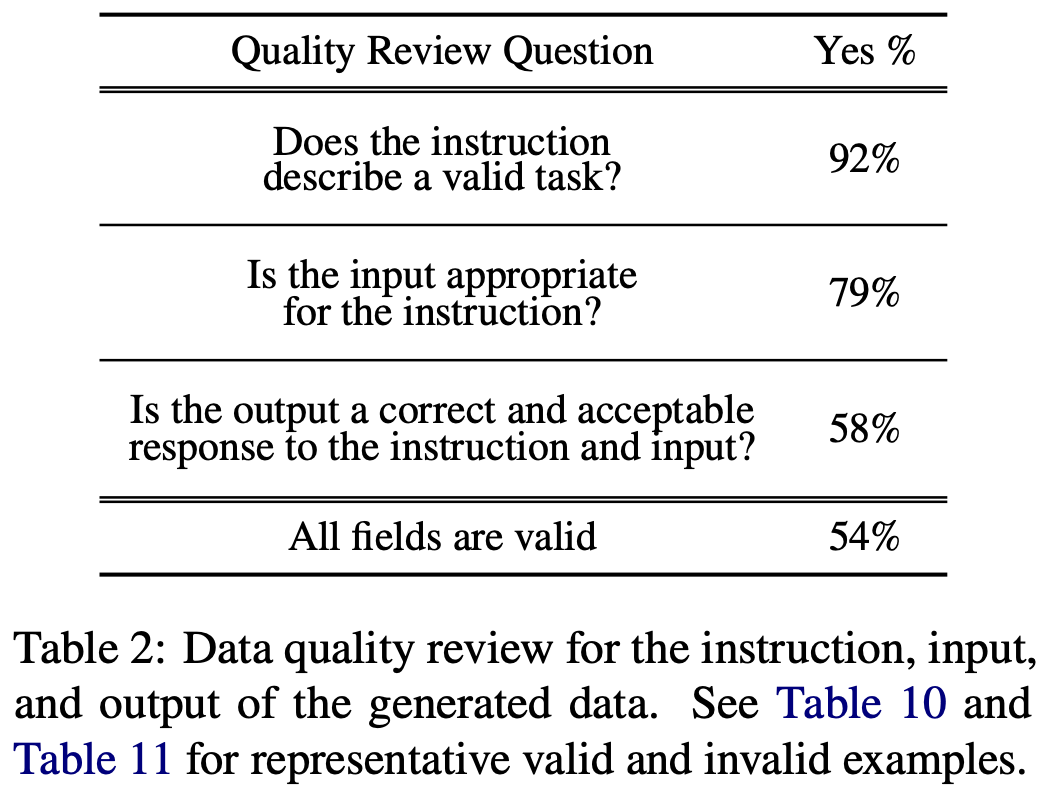
如上图,在 52k 的数据中随机选择 200 个,每个 instruction 随机选一个 instance 来给人评估。
这里对于 instruction、input、output 分别进行一个判断。整体判断下来,按照抽样的内容看有效率是 54%,也就是一半左右的数据是有效的。
2.4、效果评估实验
2.4.1、SUPERNI benchmark 上评估
CRFM 团队在 SUPERNI benchmark 上做实验,它包括 119 个任务,每个任务包括 100 个句子,表现如下:
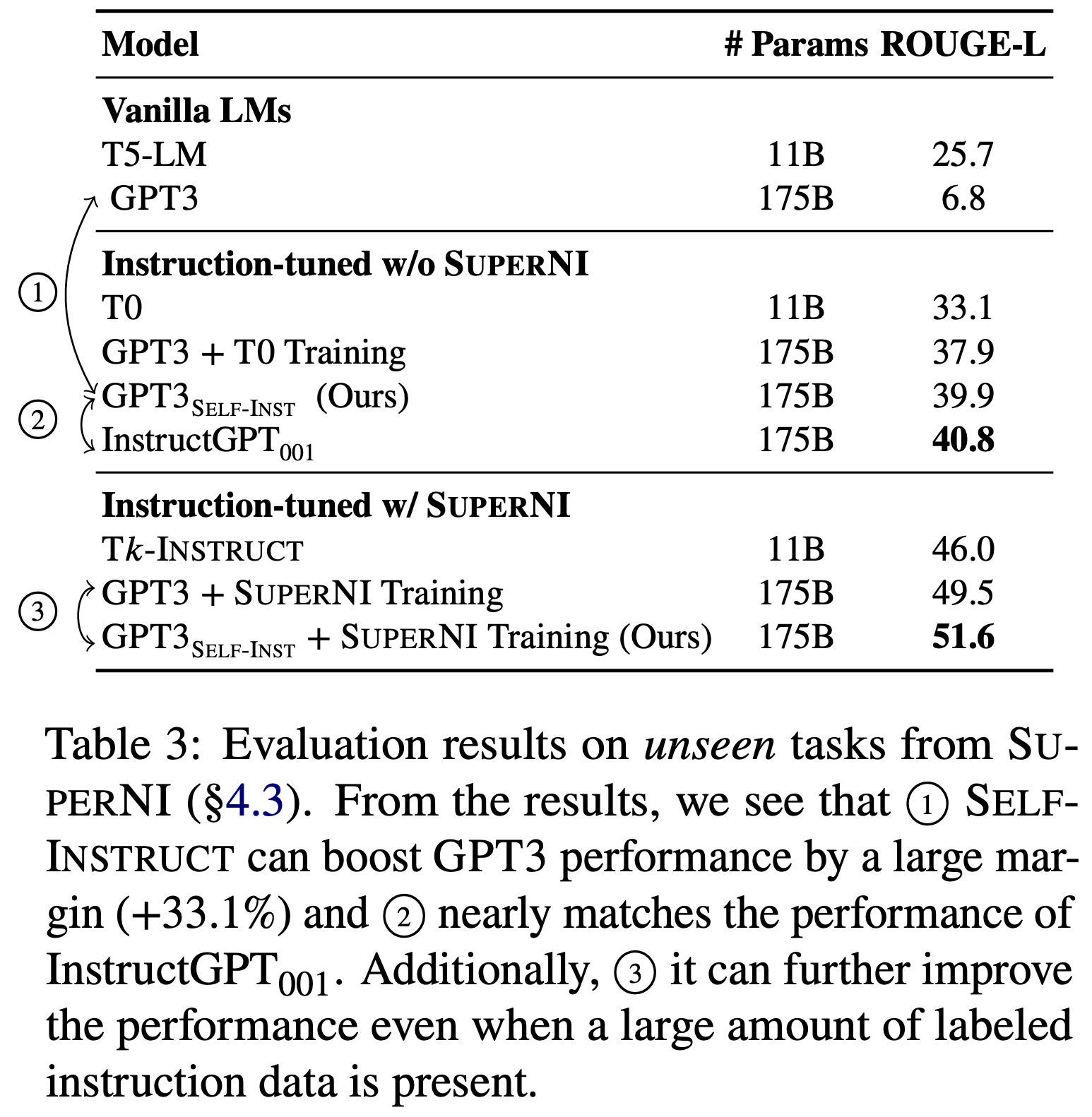
- GPT-3 和 GPT-3-self-instruct 版本比较:这里解释一下,OpenAI 为 GPT-3 提供了 finetune 的 API(收费很贵),用这个 API 基于 CRFM 团队自己用 Self-Instruct 造的数据的到了一个 fintuned GPT-3,这里我们暂且叫它是 GPT-3-self-instruct。这里两者对比,可以看到前者仅有 6.8 的分数,而后者是 39.9 的分数,可见 self-instruct 效果非常明显。
- GPT-3-self-instruct 和 InstructGPT-001 比较:两者分数差不多,但是要知道前者仅用了机器自动生成的数据 + 人工提供的少量数据,而后者开始大量人工采实现的。
- GPT-3 + SUPERNI Training vs. GPT-3-self-instruct + SUPERNI Training。在 SUPERNI benchmark 上做一下微调,对比两者发现,后者仍然是分数高一些的。
2.4.2、对新任务上面向用户的指令的泛化能力
Self-Instruct 的作者们认为,尽管 SUPERNI 在收集现有的自然语言处理任务方面非常全面,但其中大部分任务都是为了研究目的而提出的,并且倾向于分类任务。为了更好地评估指令跟随模型的实际价值,作者的一个子集策划了一组新的指令,这些指令是基于用户导向的应用而产生的。我们首先对大型语言模型可能有用的各个领域进行头脑风暴(例如,电子邮件写作、社交媒体、生产工具、娱乐、编程),然后编写与每个领域相关的指令以及一个输入-输出示例(再次强调,输入是可选的)。作者们旨在多样化这些任务的风格和格式(例如,指令可能长或短;输入/输出可以采用项目符号、表格、代码、方程等形式)。总共,作者们创建了 252 个指令,每个指令有 1 个实例。作者们认为这可以作为一个测试平台,用于评估基于指令的模型如何处理多样且不熟悉的指令。
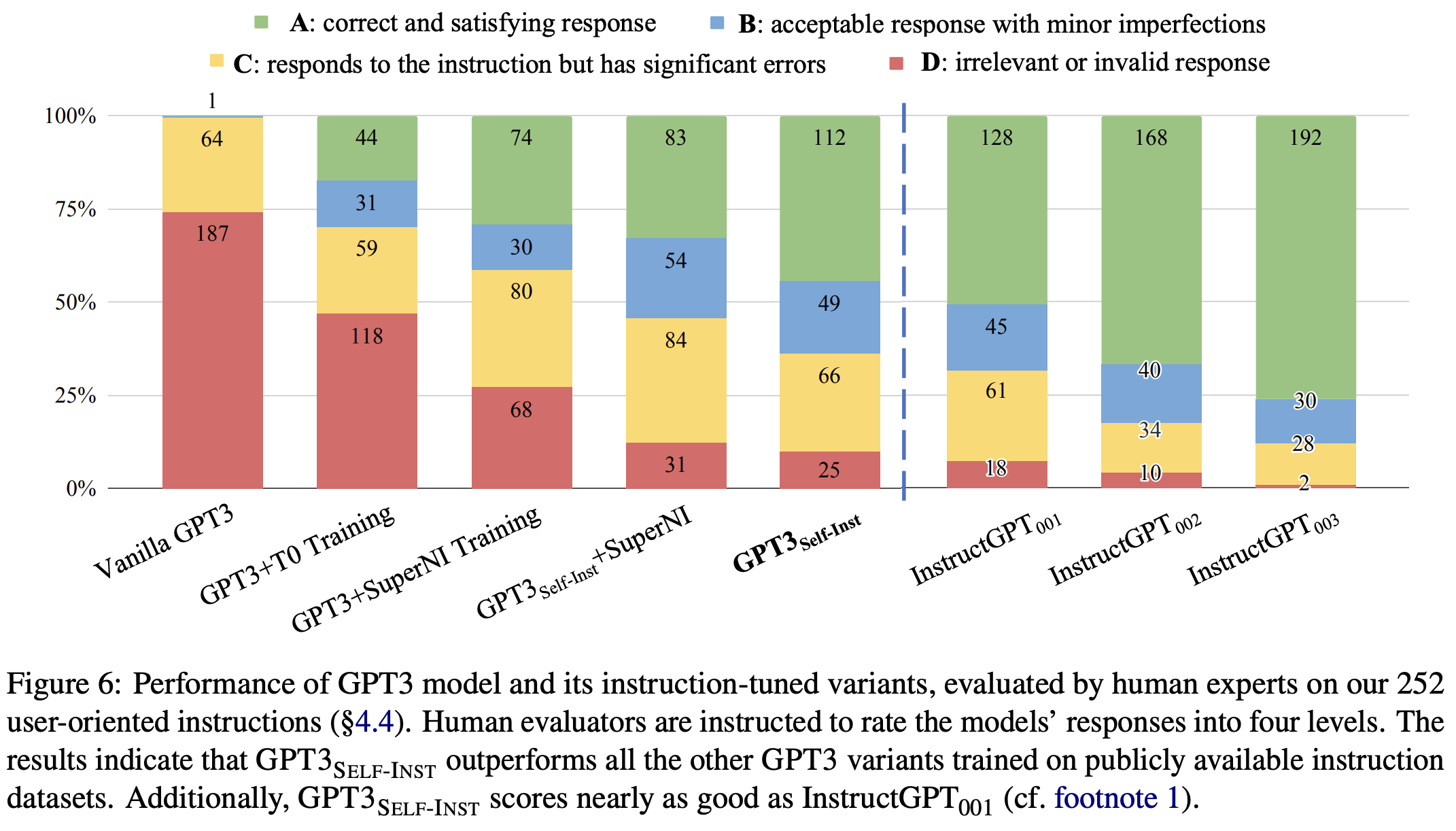
A 表示最好的,ABCD 依次,D 是表现最差的。我们可以看到,GPT-3-self-instruct 和 InstructGPT-001 已经差不多了。
2.5、Self-Instruct 的局限性
- Dependence on Large Models:Self-Instruct 的局限性最明显的一点,是需要依赖更强的大模型来作为老师辅助生成数据。
- 尾部现象(Tail Phenomena):SELF-INSTRUCT 依赖于语言模型,它将继承随着语言模型传递而来的所有限制。语言模型的最大收益对应于语言的频繁使用(语言使用分布的头部),在低频环境中可能只有最小的收益。同样,在这项工作的背景下,如果 SELF-INSTRUCT 的大部分收益偏向于在预训练语料库中更频繁出现的任务或指令,那也就不足为奇了。因此,这种方法在处理不常见和创造性的指令时可能会显示脆弱性。
- 原来语言模型中隐藏的问题也会被放大,即 Reinforcing LM bias。
3、用的什么数据微调?
了解了 Self-Instruct 之后,你就知道了,Alpaca 用的微调数据其实就是用这个框架来生成的。CRFM 团队自己花钱使用了 OpenAI 的 text-davinci-003 模型 API 生成了 52,000 条 Self-Instruct 的数据(对应 82k instances,关于具体 instance 是什么看下面 Self-Instruct 部分),然后用这些数据对 Alpaca 进行 Finetune。
- 训练数据:5.2 万条的「instruction-following」。
- 关于训练数据:发布在 https://github.com/tatsu-lab/stanford_alpaca#data-release
- 数据生成过程 https://github.com/tatsu-lab/stanford_alpaca#data-generation-process
这里用到了 Self-Instruct 框架来生成微调所需的数据,具体方法我们看下一小节。
4、Alpaca 的算力开销及微调
Alpaca 的微调总花费约不到 600 美元,具体是在 8 个 80GB 的 A100 上微调 3 个小时。其大致的微调流程如下:
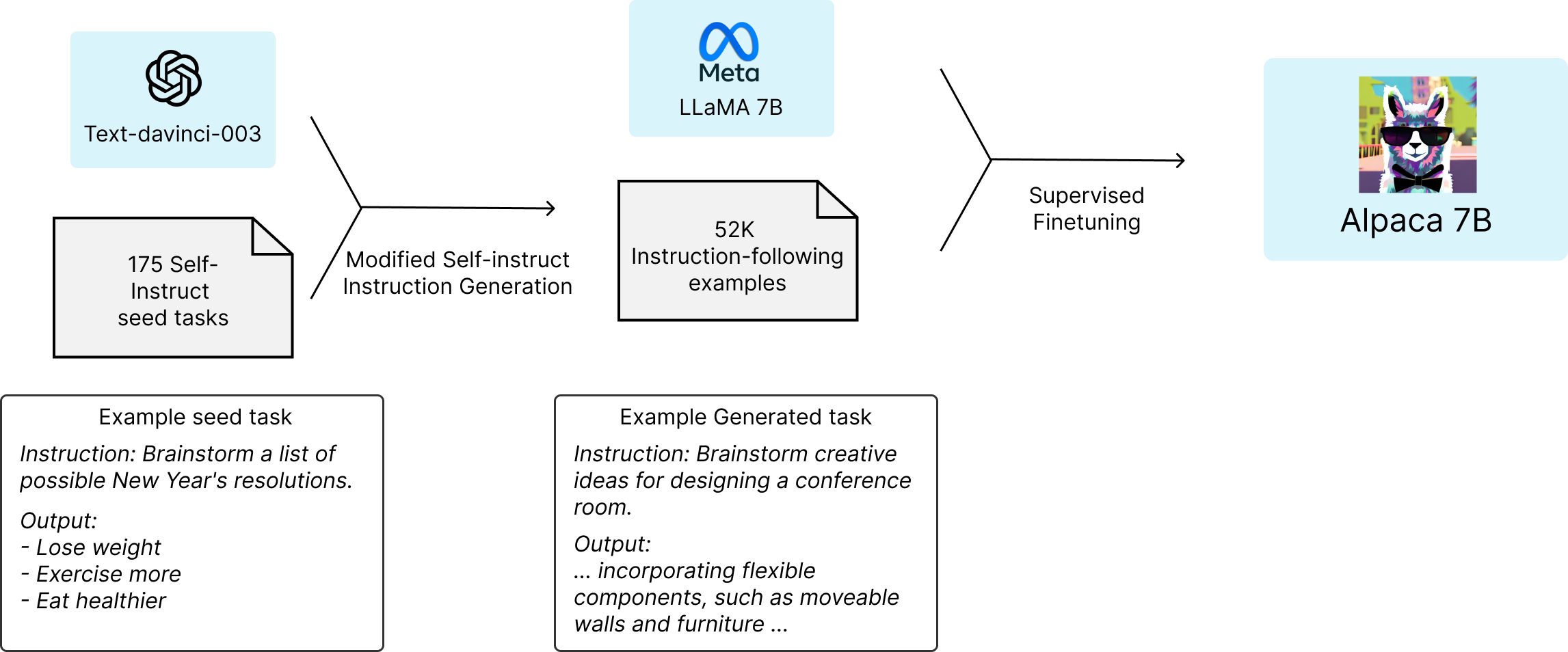
整体上,用 Self-Instruct 框架大幅地简化了生成流程(详细信息请参阅 GitHub),大大降低了成本。数据生成过程产生了 52k 个唯一指令及其对应的输出,使用 OpenAI API 的成本不到 500 美元。
5、Alpaca 性能评估
效果性能评估后,CRFM 团队声称 Alpaca 展现了许多与 OpenAI 的 text-davinci-003 相接近的表现,但 Alpaca 的规模要比 text-davinci-003 小太多了,而且微调的话费仅仅是不到 600 美元,所有人都可以低成本的复现。当然实际效果后来大家也都知道,并没有 CRFM 王婆卖瓜所说的那么好,但是这已经是一个不小的启发了。尽管大家知道微调的成本是远低于预训练的,但是 CRFM 团队直接给出了一个具体量化的结果,而且这个流程可实操落地,未来可优化的空间就自然很大。
6、Alpaca 的局限性
CRFM 团队在其官方文章中特别强调「Alpaca 仅用于学术研究,任何商业用途都是被禁止的」,并解释其原因有三个因素:
- Alpaca 基于 Meta AI 发布的 LLaMA 项目,因此也就继承了其非商用的特点。
- 用于微调的数据,是基于 OpenAI 的 text-davinci-003 模型生成的,其使用条款是禁止其生成的数据用于开发与 OpenAI 竞争的模型。
- CRFM 团队没有设计足够的安全措施(safety measures),因此 Alpaca 无法应对通用型的使用场景,只适合拿来做研究。
7、Alpaca 带来的启发及优化空间
Alpaca 是被公开放出的第一个基于 LLaMA 的微调,吹响了 LLaMA 生态被开源社区添砖加瓦繁荣起来的号角。Alpaca 虽然性能一般,但是按照同样的范式,可以有大量的优化研究可做:
- Self-Instruct 造数据的启发,以及探索如何批量制造出更好的数据。
- 使用更好的数据来 finetune。
- 训练的方法存在的优化空间也很大。
- 除了 LLaMA-7B 模型,还有 13B、33B、65B 的潜力等待挖掘。
- 引发了数据有效性的讨论。
8、Alpaca.cpp 发布
Stanford CRFM 团队的 Alpaca 发布后的四天,一个在多种个人计算设备上就能跑起来的 Alpaca.cpp 被发布,由加州的 Kevin Kwok 将 LLaMA.cpp 与 Alpaca 做了整合。
Alpaca.cpp 的项目地址为 https://github.com/antimatter15/alpaca.cpp。 如果想在本地设备上运行推理,也非常简单,以船长在 macOS 下为例,首先 clone 项目到本地:
mikecaptain@CVN % git clone https://github.com/antimatter15/alpaca.cpp
mikecaptain@CVN % cd alpaca.cpp
然后下载训练好的模型权重文件,然后编译,运行推理。
mikecaptain@CVN % wget -O ggml-alpaca-7b-q4.bin -c https://gateway.estuary.tech/gw/ipfs/QmQ1bf2BTnYxq73MFJWu1B7bQ2UD6qG7D7YDCxhTndVkPC
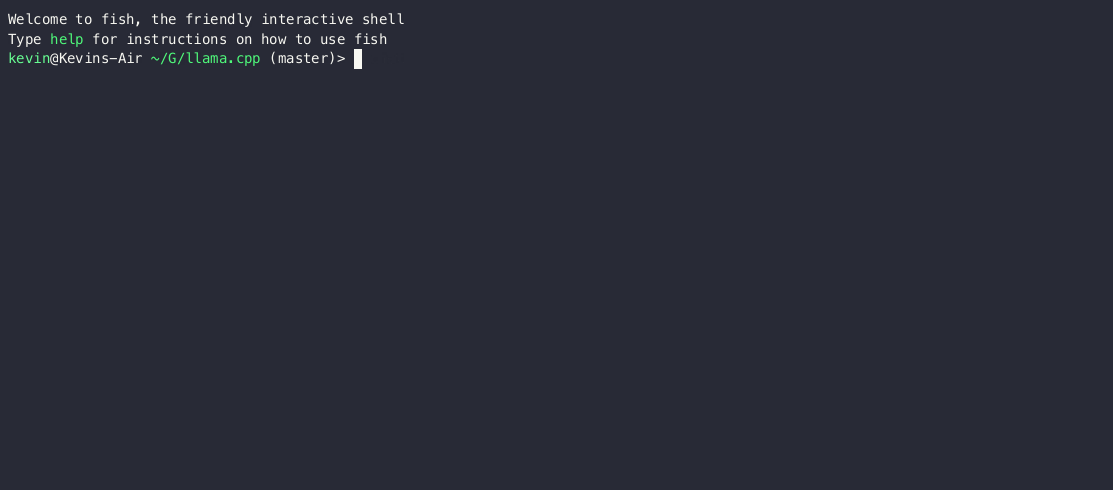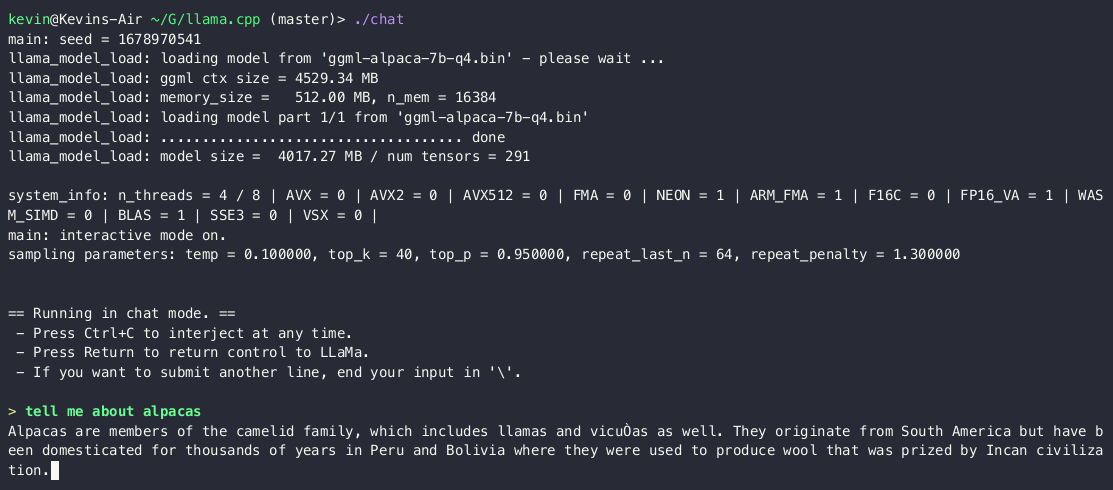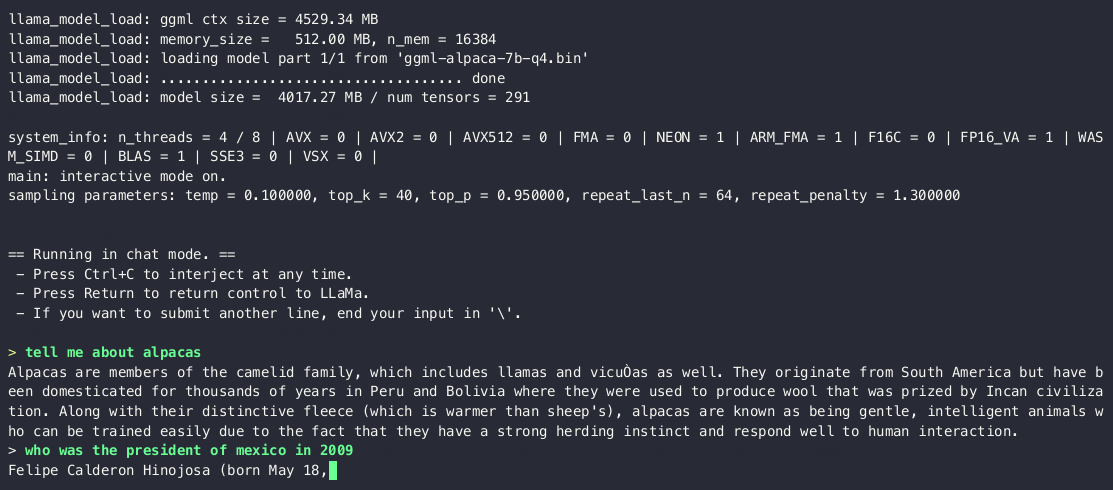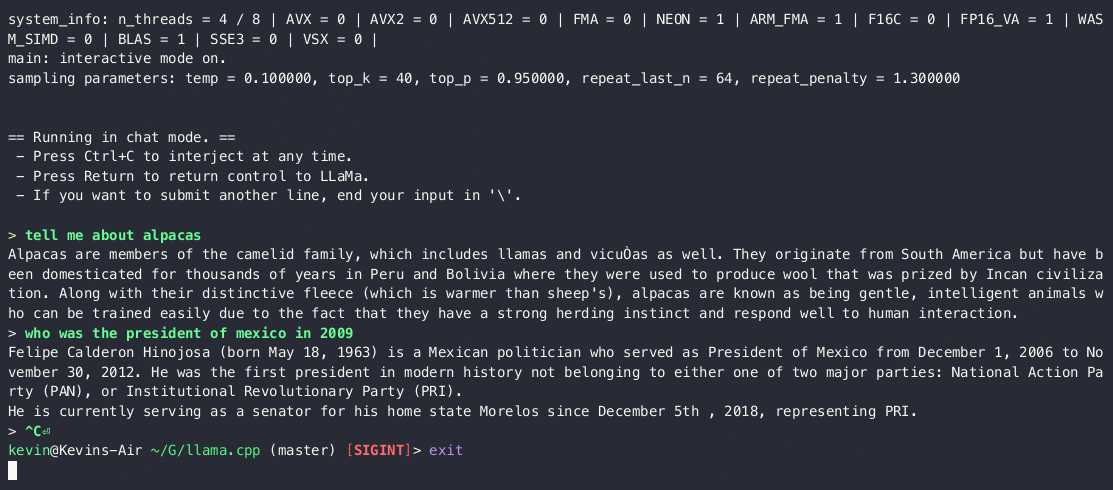
mikecaptain@CVN % make chat
mikecaptain@CVN % ./chat
运行推理效果演示如下:
参考
- https://crfm.stanford.edu/2023/03/13/alpaca.html
- https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform
- https://pujols.pixnet.net/blog/post/23619904
- https://arxiv.org/abs/2212.10560
- https://github.com/yizhongw/self-instruct
- https://www.bilibili.com/video/BV1jM411M7Ls/?spm_id_from=333.337.search-card.all.click&vd_source=4555ef51cf600ab2c791b34a0933a76d
- https://github.com/antimatter15/alpaca.cpp4