上船跑模型之 MacBook 上运行 LLaMA 7B 和 13B 原始模型
本文目录
一、LLaMA 预训练模型下载
LLaMA 是什么?关于 LLaMA 的介绍,看这篇《Meta 推出开源 LLaMA,用 1/10 参数规模打败 GPT-3,群”模”乱舞的 2023 拉开序幕》。
聊了 LLaMA 后,接下来,下载 LLaMA 模型文件,这里略去下载地址(网上很多,但普遍地址有效生命周期不长)。
─ models
├── 7B
│ ├── checklist.chk
│ ├── consolidated.00.pth
│ └── params.json
├── 13B
│ ├── checklist.chk
│ ├── consolidated.00.pth
│ ├── consolidated.01.pth
│ └── params.json
├── 30B
│ ├── checklist.chk
│ ├── consolidated.00.pth
│ ├── consolidated.01.pth
│ ├── consolidated.02.pth
│ ├── consolidated.03.pth
│ └── params.json
├── 65B
│ ├── checklist.chk
│ ├── consolidated.00.pth
│ ├── consolidated.01.pth
│ ├── consolidated.02.pth
│ ├── consolidated.03.pth
│ ├── consolidated.04.pth
│ ├── consolidated.05.pth
│ ├── consolidated.06.pth
│ ├── consolidated.07.pth
│ └── params.json
└── tokenizer.model
因为文件太大,估计会出现多次断点续传,所以一定要校验下文件是否正确,正确与否与 checklist.chk 文件对比。比如:
mikecaptain@CVN % md5sum 7B/consolidated.00.pth
6efc8dab194ab59e49cd24be5574d85e
二、用 ggerganov/llama.cpp 运行
1、LLaMA 7B 版本
1.1、下载 LLaMA.cpp 项目
mikecaptain@CVN % git clone git@github.com:ggerganov/llama.cpp.git
mikecaptain@CVN % cd llama.cpp
mikecaptain@CVN % make
1.2、准备 llama 7B 环境
mikecaptain@CVN % conda install pytorch numpy sentencepiece
The first script converts the model to “ggml FP16 format”:
mikecaptain@CVN % python convert-pth-to-ggml.py models/7B/ 1

这样会得到一个 13GB 的文件 models/7B/ggml-model-f16.bin,然后再运行脚本 quantize 用来把 models/7B/ggml-model-f16.bin 转为 4-bits 版本:
mikecaptain@CVN % ./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin 2
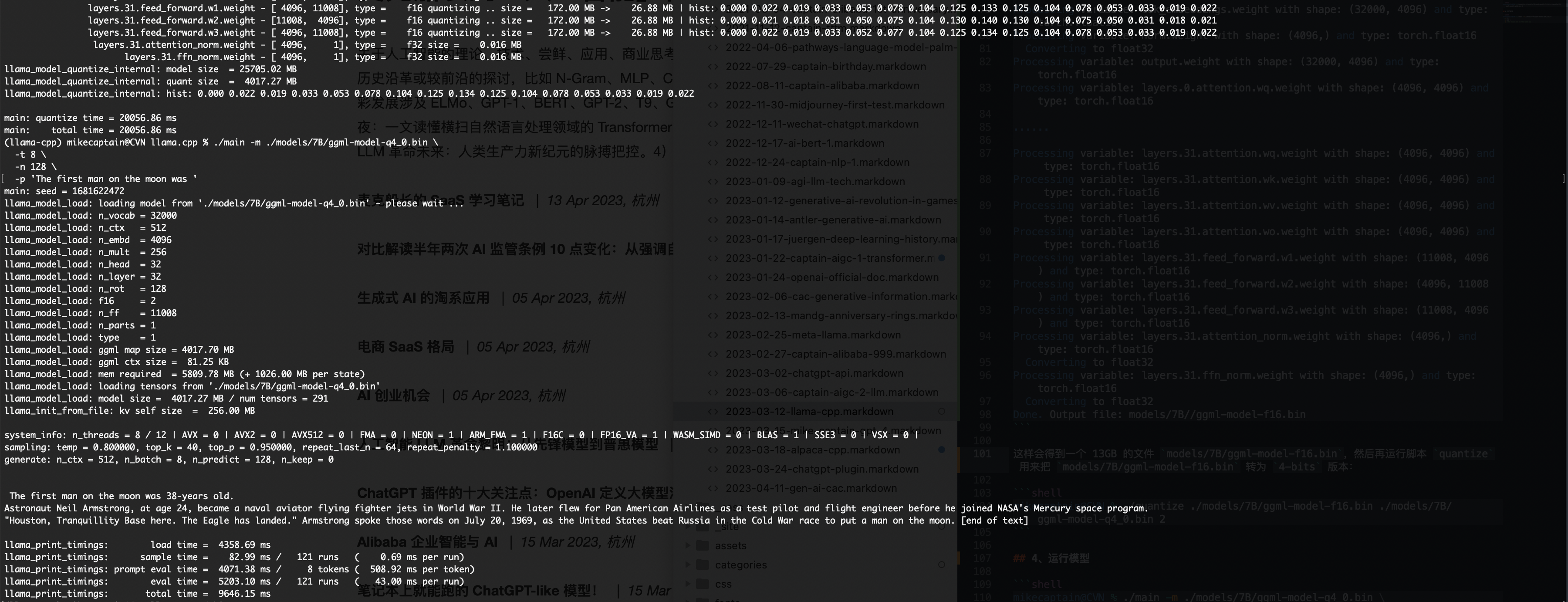
这样会生成一个 3.9GB 的 models/7B/ggml-model-q4_0.bin 文件。
1.3、运行 LLaMA 7B 模型
脚本 main 用于启动,使用刚得到的 models/7B/ggml-model-q4_0.bin 模型文件。
mikecaptain@CVN % ./main -m ./models/7B/ggml-model-q4_0.bin \
-t 8 \
-n 128 \
-p 'The first man on the moon was '
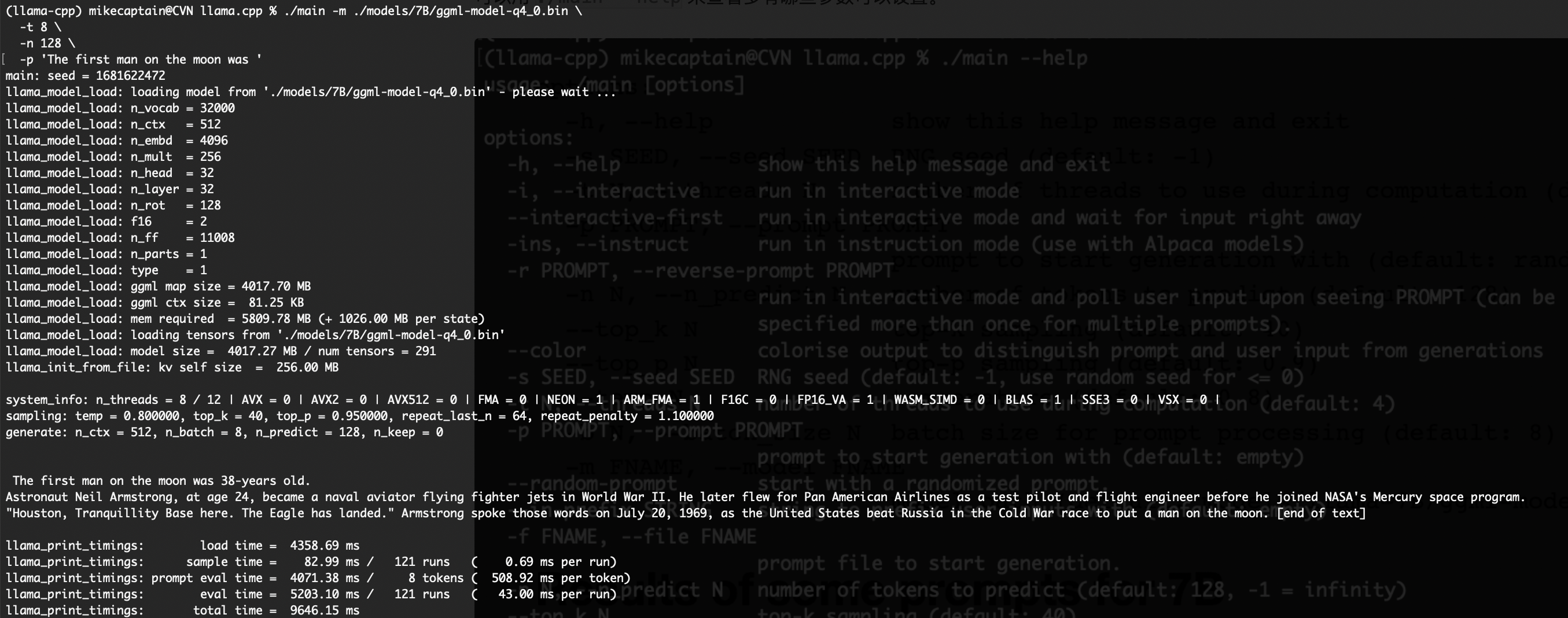
可以看到续写的内容是:
The first man on the moon was 38-years old. Astronaut Neil Armstrong, at age 24, became a naval aviator flying fighter jets in World War II. He later flew for Pan American Airlines as a test pilot and flight engineer before he joined NASA’s Mercury space program. “Houston, Tranquillity Base here. The Eagle has landed.” Armstrong spoke those words on July 20, 1969, as the United States beat Russia in the Cold War race to put a man on the moon. [end of text]
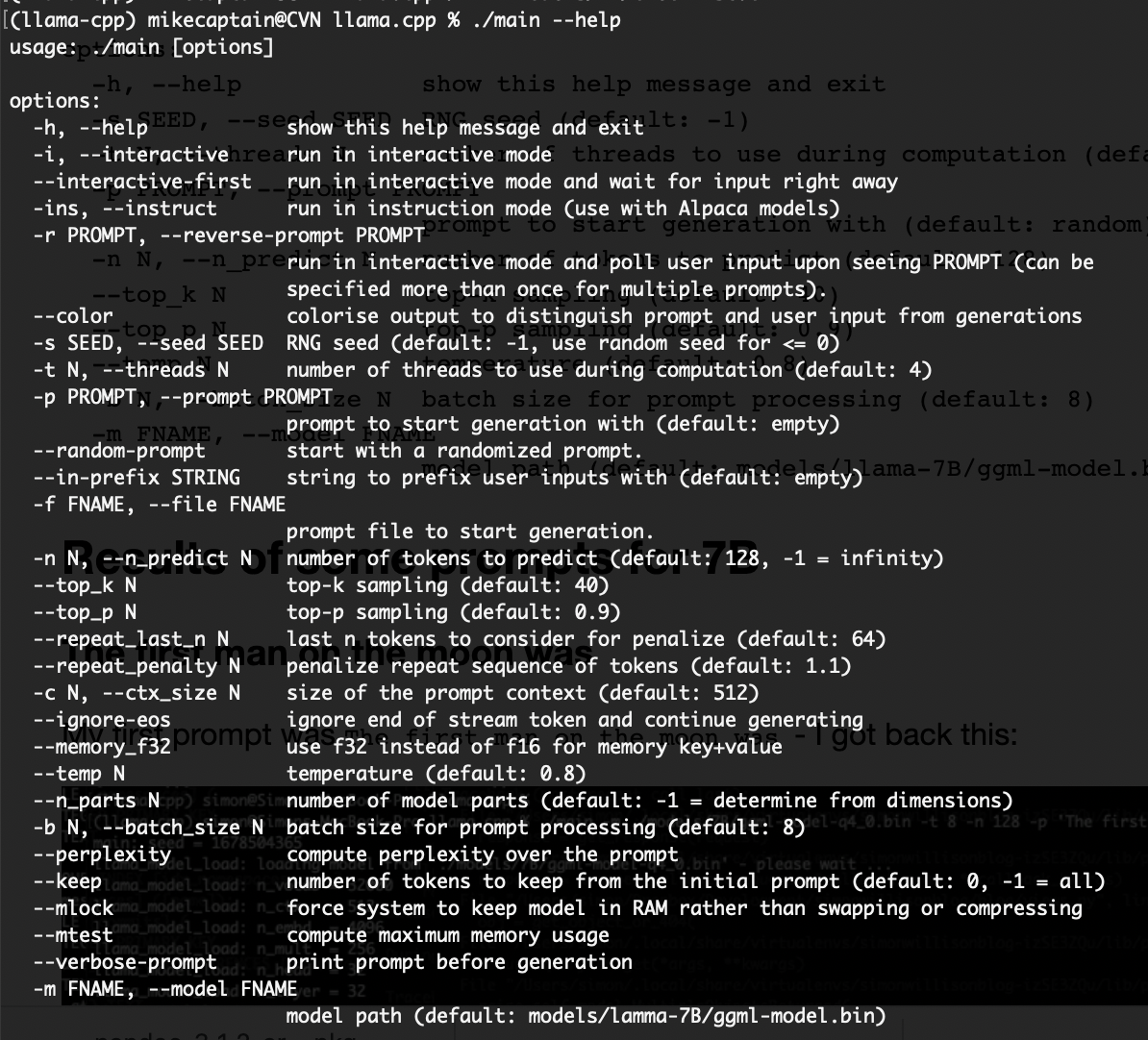
可以用 ./main --help 来查看多有哪些参数可以设置。
2、LLaMA 13B 版本
2.1、准备 LLaMA 13B 环境
运行如下命令,生成文件 26.03GB 大小的 ggml-model-f16.bin:
mikecaptain@CVN % python convert-pth-to-ggml.py models/13B/ 1
再运行如下命令,生成文件 8.14GB 大小的 ./models/13B/ggml-model-q4_0.bin:
mikecaptain@CVN % ./quantize ./models/13B/ggml-model-f16.bin ./models/13B/ggml-model-q4_0.bin 2
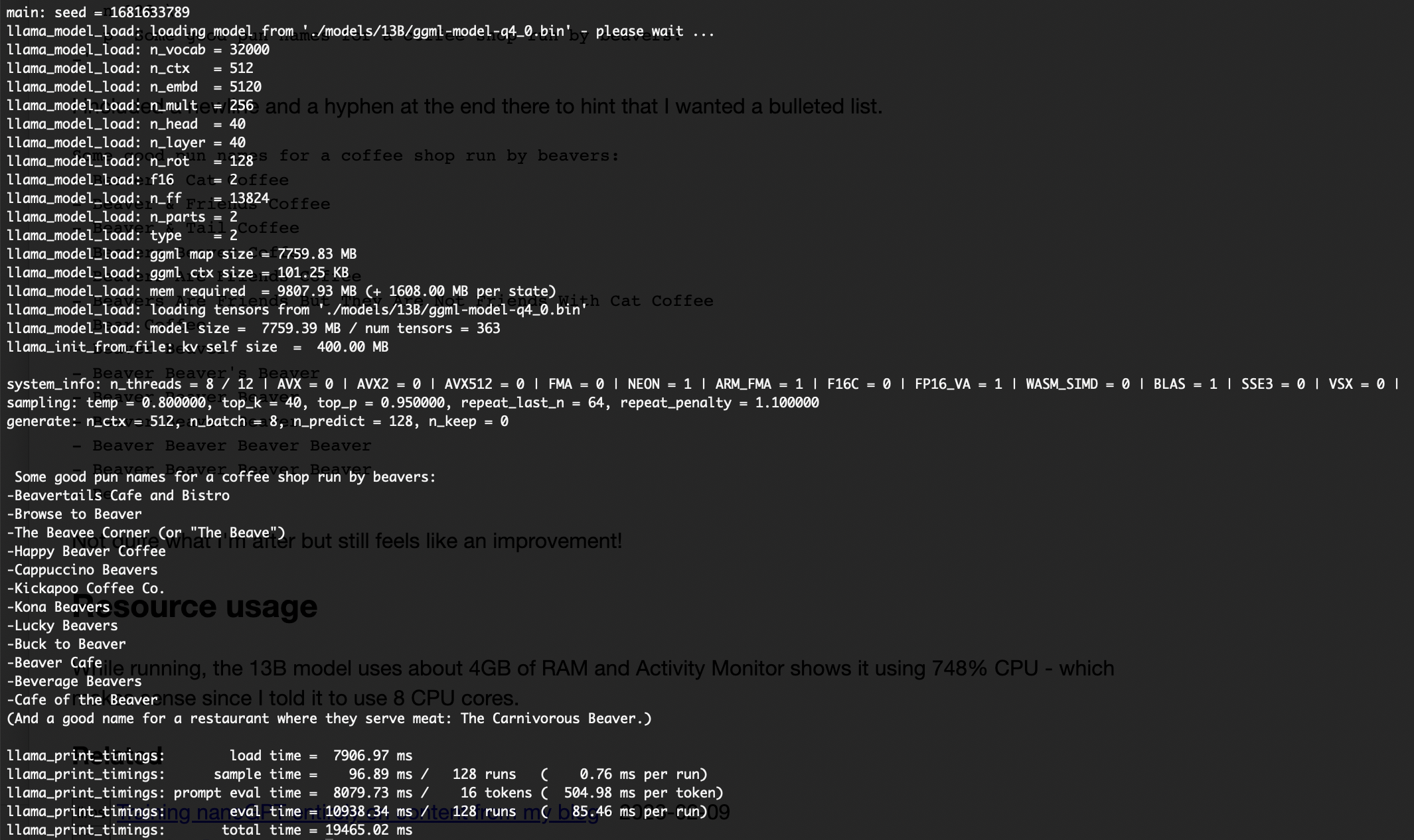
2.2、运行 LLaMA 13B 模型
mkkecaptain@CVN % ./main \
-m ./models/13B/ggml-model-q4_0.bin \
-t 8 \
-n 128 \
-p 'Some good pun names for a coffee shop run by beavers:
-'