自然语言处理 AIGC 近年的发展脉络、关键论文、技术里程碑和商业应用
- 作者:麦克船长(钟超)
- 微信:sinosuperman
本文目录
- 一、自然语言处理领域近年的发展关键节点
- 二、学术里程碑:几篇重量级论文
- 0、提出 Attention 机制的《Neural Machine Translation by Jointly Learning to Align and Translate》(2015)
- 1、提出 Transformer 的《Attention is All You Need》(2017)
- 2、ELMo: Deep contextualized word representations
- 3、GPT-1:Improving Language Understanding by Generative Pre-Training
- 4、BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2018)
- 5、GPT-2:
- 6、GPT-3: Language Models are Few-Shot Learners(2020)
- 7、InstructGPT
- 其他的重量级论文
- 三、行业里程碑
- 四、成本
- 五、业内应用
- 五、行业内哪些人的言论值得我们日常重点关注
- Reference
一、自然语言处理领域近年的发展关键节点
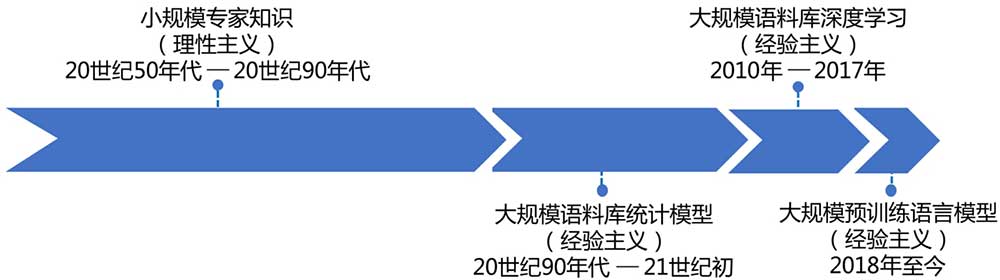
1、从理性主义到经验主义
自然语言处理(Natural Language Processing,简称 NLP),一开始走的是专家路线,也就是想「白盒化」来解构对自然语言的理解,这被称为「符号主义(Symbolism)」。符号主义的背后,是人类对自己用符号系统基于逻辑来完全数字化自然语言的自信。反正这条路目前是没走出来,你要非说「这其实是自负」,暂时人工智能专家们也无可辩驳。沿着这个路径的研究一直占据人工智能主流到 20 世纪 90 年代。
这里我们想想,自然语言处理,其实是两个过程,一个是输入,即对自然语言的理解,一个是输出,即近期有点火的概念 AIGC(Artificial Intelligence Generated Content)。我们这里说说前者,人类学习语言的过程,哪有什么符号系统,哪有什么逻辑,就是被疯狂输入,然后经过很多个月之后,一个小 baby 就学会说话了,这个过程没有「理性主义」的痕迹,只有「经验主义」的胜利。那么 AI 学人话,能这样吗?
于是就有了所谓「联结主义(Connectionism)」:你知道人的神经元网络吧?这个是一个个神经元,相互联结组成一个网络,通过这个网络来非常「黑盒化」地学习自然语言。至于这个网络里的每一个细节,我们不甚清楚,但就是可以通过这个网络模型学会自然语言,这就是一种「经验主义」。从 20 世纪 90 年代,人工智能领域就是沿着这个方向取得了巨大进展的。要注意一点,经验主义地路径解决 NLP 问题,并不等同于神经网络,但它是目前最有效的。
2、经验主义的早期,还不是深度学习
最初的经验主义,还是主要通过人工对特征进行「经验性地」提取,对计算机来说不要让它求甚解,直接给它喂这些梳理好的「特征」就好了。而这个需要一定的专业领域知识储备,加上人工地提取特征的操作过程,被称为「特征工程」。
可以看出来,「特征工程」的人工工作量非常大,可以说是名副其实的「人工」智能了(此处捂脸)。但这已经比此前的、有点理想的那种构建符号系统的想法,要务实多了,也确实在解决问题的实用主义上也好得多。以这个为主流的研究,大概持续到 2010 年代。
3、撇开特征,让机器「囫囵吞枣」地学吧
要经过「人工」对特征进行研究、提取,实在是太难了,你说是「经验主义」,其实我个人认为有点介于「理性主义」与「经验主义」之间。毕竟还是非常需要人进行非常专家级地梳理的。于是,更囫囵个儿地给机器喂数据,让机器学会的方向,逐渐成为主流。能这样的前提,是牛逼算力的大发展,以及海量数据集的大规模沉淀,所以才会在 2010 年代爆发。
这囫囵吞枣的学法,目前主要都是基于深度神经网路的表示学习方法实现的。为啥说「深度神经网络」,因为「从输入到输出」是有一层又一层的神经网络,第一层接收原始的自然语言输入,这么多层的神经网络就被称为深度神经网络。这个过程显著地避免了「特征工程」的人工高成本。
4、囫囵个儿地学习,省去特征工程的人工,但也少不了标注的人工
虽然省去了需要专家的「特征工程」,但是这个「囫囵个儿学习法」还是需要依赖标注数据的,也就是「监督学习」。通过先学习大量有人工标注地数据,构建好深度神经网络后,再对测试数据进行验证,最后再用于使用。能不能把人工标注也给省了?或者至少不需要海量标注吧。
5、自监督学习法,让我们省去人工标注
大家上中学的时候做过英语试卷里的「完形填空」吗?为什么我们根据一个填空的上下文,能推测出这个空应该填什么词?那我们是不是可以根据这个原理,把一段段完整的文字内容挖词进行训练学习?没错,这个挖掉的词,就可以当做曾经的「人工标注」,上年文就是训练数据。但是需要海量的数据,怎么办?
好在书籍、互联网网页是我们最好的数据来源,而且数据量极其巨大,于是这就解决了人工个标注问题。由此衍生出来的方法,就被成为「自监督学习(Self-Supervised Learning)」。
6、用原始的任务训练出来的模型,能迁移去解决新任务吗?
这是一个迁移学习问题,这也就引出了「预训练(Pre-Training)」,最近火到出圈的「ChatGPT」最后两个字母「PT」就是「预训练」。正如「预训练」这个名字,我们先对一些原始任务用大量数据对一个模型进行训练(这个过程其实就叫预训练),然后对于实际要解决的各种任务,再使用少量数据对模型进行精调(Fine-Tune),从而得到一个解决具体问题的模型。
这样的方式,让面对具体任务(可以叫下游任务,或者目标任务)时可以省去很多训练,所以对这种模型叫做「预训练模型」。因此上游任务的训练,就变得非常有复用性、通用性价值,而不是每次面对新任务构建新模型来训练。沿着预训练模型,NLP 取得了非常多的突破。这个技术趋势,是从 2017 年 Transformer 模型在论文《Attention is All You Need》被提出后开始的,在论文中作者使用了大量的未标记的语言数据进行自监督学习,以学习 Transformer 模型的语言表示。然后,在这个自监督学习的模型的基础上,再使用少量的标记数据进行进一步训练,以解决具体的目标任务。
7、从理解到生成,NLP 是最直面 AIGC 最硬核难题的领域
我们再说回到前面提到的人工标注,从这点来理解所谓「任务」。人工标注,是主观性很强的。在图像处理、语音识别两个领域,标注数据的复用性很强,所以可以积累大的数据标注集,这是有积累沉淀价值的,比如 CV 领域鼎鼎大名的 ImageNet 图像数据集。但是 NLP 领域的任务复杂、多样,很难像图像处理、语音识别那样单纯地得到大量有价值标注。什么意思呢?这与我们在不同领域面对的任务有关。
比如给一副画,对于绝大多数需要输入这幅画的任务来说,标注出它是一副油画、作者梵高、画中有星空等等,都是必须的。比如对于一个人脸识别,哪里是眼睛、鼻子、嘴巴,也是从任务层面非常通用的。语音识别就更有通用性了。但是对于一句自然语言,一个随机的任务需要什么信息,这非常难以沉淀通用。
从这个角度说,一个「图像处理」任务一般是要输出这个图像里有什么内容,一个「语音识别」任务一般是要输出这段语音的文字内容是什么。但是一个「自然语言处理」任务一般是要干嘛?鬼知道要干嘛,但肯定大多数时候是要先生成一段话作为回应,这也就是「自然语言生成」。
所以 NLP 领域的 NLG(Natural Language Generation)面对着最多可能性的任务,也就是最直面 AIGC 核心问题的领域。
8、数据和算力有了,还不够
我个人认为,预训练这个方向之所以正确,就是因为它在推动 AGI(Artificial General Intelligent)。这背后是一个基本哲学问题:我们应该把劲儿使在推动 AGI,还是应该认为每个领域都应该有自己独有的模型?
这个问题的答案,在我看来是笃定的。AI 目前面对的还是人类思考的问题,而人面对的问题去构建的人脑学习模型,并没有呈现出在不同领域里人脑的学习方式有显著差异,更何况计算机能容纳的学习能力显然更广、更深。因此我很笃定,我们一定是要构建 AGI,为什么 AGI 将解决我们方方面面的问题。
那么一个预训练模型,在下游能解决的问题越广,越说明这是在构建 AGI。但是反过来对上游的预训练模型的要求,就是它最好模型参数越多越好,这样能容纳的下游任务也就可能越多样。因此我们现在知道的 ChatGPT 背后的 OpenAI 公司此前研发的 GPT-3 已经有 1750 亿个参数了,这就是 —— 大模型。
所以目前沿着预训练方向发展的自然语言处理领域,已经进入了「大模型、大数据、大算力」时代。
二、学术里程碑:几篇重量级论文
以下重量级的论文,每一篇都不短,B 站上有一些二手解读,虽然二手但是也值得高效地看下,这些论文我罗列如下。我的理解也不深,欢迎随时交流。
0、提出 Attention 机制的《Neural Machine Translation by Jointly Learning to Align and Translate》(2015)
Bahdanau 等人在 2015 年提出了 Attention 机制,论文地址:https://arxiv.org/pdf/1409.0473.pdf
1、提出 Transformer 的《Attention is All You Need》(2017)
论文地址:https://arxiv.org/pdf/1706.03762.pdf
Google 的 Lamda、BERT,OpenAI 的 GPT-3 都是基于 Transformer 的。
《Attention is all you need》是一篇颇具影响力的自然语言处理(NLP)论文,由 Google 在 2017 年发表。这篇论文提出了一种叫做 Transformer 的模型架构,这种模型架构不依赖于递归神经网络(RNN)或卷积神经网络(CNN)等传统的深度学习架构,而是使用了注意力机制(attention mechanism)和多头注意力(multi-head attention)来捕捉序列间的依赖关系。
看到有人说「Transformer 基本宣告了 LSTM 在 NLP 领域的终结」。Transformer 模型在 NLP 领域内获得了广泛的应用,并且因为其较好的并行化能力,在计算资源有限的情况下也能够获得较好的性能。Transformer 模型也被广泛应用于其他领域,如计算机视觉、音频处理等。
2、ELMo: Deep contextualized word representations
ELMo 是 Embeddings from Language Models 的缩写,刚好是《芝麻街》中一个角色的名字,是在 Peters 等人于 2018 年在 ACL(美国计算机学会计算语言学会议,NLP 领域顶级会议之一)上发表的论文《Deep contextualized word representations》中被提出来的。
ELMo 是一种预训练模型,基于深度双向递归神经网络(biLSTM),可以用来生成词嵌入(word embeddings)。ELMo 使用了大量未标记的文本数据训练,并使用了多层双向递归神经网络来学习。
3、GPT-1:Improving Language Understanding by Generative Pre-Training
4、BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding(2018)
BERT 模型是在一篇于 2018 年发表的叫做《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》的论文中被提出来的,BERT 是 Bidirectional Encoder Representations from Transformers 的缩写。我觉得这个名字有点硬凑出来的意思,BERT 也是《芝麻街》里一个角色的名字,我想就是为了跟 ELMo 凑一块儿怕它孤单吧。这篇论文带来的最大突破性变化有:
- 在语言模型预训练中引入双向信息:传统的预训练语言模型(比如 word2vec、GloVe)通常只考虑了单向的信息(前面的词语)。BERT 模型则同时考虑了前后的词语,从而更好地捕捉句子的上下文信息。
- 在预训练中引入自监督学习任务。
关于 BERT,我这里写了一篇背景介绍、用例试跑、优劣势分析:《你可能已经听说 GPT-3,但是你也不能不知道 BERT —— 跟我一起用 BERT 跑个小用例》
5、GPT-2:
6、GPT-3: Language Models are Few-Shot Learners(2020)
这篇来自 OpenAI 的论文,提出了「小样本学习(Few-Shot Learning,FSL)」的新训练方法,可以在小样本的情况下取得优秀的表现。
7、InstructGPT
2022 年 3 月 OpenAI 发表《Training language models to follow instructions with human feedback》论文,提出 InstructGPT。这篇论文的初衷,是 OpenAI 将其 GPT-3 全面开始考虑 Alignment 的开始。
其他的重量级论文
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context(2019)
- RoBERTa: A Robustly Optimized BERT Pretraining Approach(2019)
- T5: Exploring the Limits of Transfer Learning witha Unified Text-to-Text Transformer(2020)
- ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(2021)
- ERNIE-ViL: Vision and Language Pre-training for Image Captioning and VQA(2021)
- ……
三、行业里程碑
2017 年 8 月,Andrej Karpathy 在其 Twitter 上发文称「很遗憾,梯度下降(实现的 AI 模型)代码写得比你好」。同年 11 月 Andrej 在博客上表示,软件 2.0 将会区别于软件 1.0 时代,程序将由更抽象的、基于神经网络权重的程序语言编写。
2018 年 OpenAI 推出了无监督的、基于强化学习的第一代 GPT。
2019 年情人节,OpenAI 发布 GPT-2,当时被称为史上最强的「通用」自然语言处理模型,基于 Transformer,拥有 15 亿个参数,使用含有 800 万网页内容的数据集训练。
2020 年 6 月,拥有 1750 亿个参数的 GPT-3 面世,这个模型的训练量是 GPT-2 的十倍不止,并开放了商业化 API 共使用,不到一年时间发展出约 300 家企业客户。
2021 年 1月,Google 推出 Switch Transformer 模型,参数量 1.6 万亿,是人类首个万亿级参数的语言模型。
2021 年 6 月,微软与 OpenAI 共同推出代码辅助生成 AI 工具 GitHub Copilot.
2022 年 1 月,OpenAI 发布基于 GPT-3 微调的模型 InstructGPT(包括 text-davinci-001、text-davinci-002、text-davinci-003),微调主要来自于 RLHF(Reinforcement Learning via Human Feedback)。
2022 年 5 月,杭州 AI 领域初创公司「感知阶跃(ZMO.ai)」宣布完成由高瓴资本领投、GGV Capital 和 GSR Ventures 跟投的 800 万美元 A 轮融资。
2022 年 10 月 19 日,Jasper.ai 宣布完成由 Insight Partner 领投,Coatue、(BVP)Bessemer 以及 IVP 等机构跟投的 1.25 亿美元 A 轮融资,估值达到了 15 亿美元,Jasper AI 从产品上线至今仅 18 个月。
2022 年 11 月底,OpenAI 推出基于 GPT-3.5 的 ChatGPT 对话系统,震惊全球。项目地址:https://chat.openai.com 。
2022 年 12 月底,专注于各 AI 闭源项目的逆向工程的 Philip Wang 发布了 PaLM+RLHF 的文本生成开源模型,类似于 ChatGPT。该项目基于 Google 的大型语言模型 PaLM 和带有人类反馈的强化学习(RLHF),拥有 5400 亿个参数。项目地址:https://github.com/lucidrains/PaLM-rlhf-pytorch 。
四、成本
目前成本主要有三方面:大模型、大数据、大算力。这其中最昂贵的成本首先是算力。下面有几个数据可以作为参照:
- 2020 年的一项研究表明,开发一个只有 15 亿个参数的文本生成模型的费用高达 160 万美元。
- 2022 年 7 月,为了训练拥有 1760 亿个参数的开源模型 Bloom,Hugging Face 的研究人员耗时三个月,使用了 384 个英伟达 A100 GPU。
- OpenAI 的文本生成 GPT-3(具有大约 1750 亿个参数)的运行成本约为每年 87,000 美元。
- Hugging Face 训练 Bloom 花了三个月的时间。
五、业内应用
因为图片生成的容错率非常高,也就是在应用上的包容度更高,相比之下文本或语音的生成,是对结果容错非常低的,比如不容许事实错误、逻辑错误等等。这类的应用,我们能想到:
- 虚拟客服(可以乱真的)
- 智能助理:AI 家庭教师、AI 非诉律师、AI 医生助手、AI 新闻编辑、AI 设计助理
- 智能翻译
- 智能导购员:如果叠加虚拟人技术、语音合成技术,可以应用于电商
- AI 广告公司:替代传统广告公司
- AI 程序员助手:更高智能的辅助代码生成
- 部分场景下的美术工作者:游戏素材生成、海报生成
我们可以看到,AI 带来的这一波机会,都是曾经常说的「人不会被 AI 替代」的领域,也就是一些创作创意创新型工作,其中的中低端部分会因为成本因素而极力推动 AI 应用的发展。
所以下面除了大家耳熟能详的 CV 领域的 AIGC 产品 Disco Diffusion、MidJourney、DALL·E 2、Stable Diffusion 之外,我们重点关注非图片生成类的应用。
- 用于营销场景的 AI 写手与图像生成工具「Jasper.ai」,常被用于生成互联网营销文案(比如用于 Instagram、Tik Tok、Facebook、博客、email、论坛帖子 等等)。
- 2021 年 6 月,微软与 OpenAI 共同推出的的代码辅助生成 AI 工具「GitHub Copilot」发布。
- 文案神器「Copy.ai」:
- 虚拟客服「DialogFlow」,能理解电话、语音内容等输入,并且给出文本或语音合成的输出。
- 2021 年年底,西湖心辰公司发布「Friday AI 智能协作系统」,并且目前也做了商业化。
五、行业内哪些人的言论值得我们日常重点关注
这些人的言论都值得我们关注:Sam Altman、Andrej Karpathy、Elon Musk。
Andrej Karpathy 在其 Medium 博客上提到:
我们都熟悉的软件 1.0 的「经典堆栈」(The classical stack)是由 Python、C++ 等语言编写的,它由程序员编写的明确的计算机指令组成。通过编写每一行代码,程序员标识了程序空间中具有某些期望行为的特定点。
相比之下,软件 2.0 是用更抽象、不友好的人类语言(如神经网络的权重)编写的,没有人参与编写这些代码,因为权重数量很多(典型的网络可能有数百万个),并且直接用权重编写代码有一定困难(我尝试过)。
不过打那之后 Andrej 在其博客上就再未说过一句话。
OpenAI 创始人兼 CEO Sam Altman 曾表示:
十年前的传统观点认为,人工智能首先会影响体力劳动,然后是认知劳动,再然后,也许有一天可以做创造性工作。现在看起来,它会以相反的顺序进行。
通用人工智能的建成会比大多数人想象得更快,并且它会改变大多数人想象中的一切。」
另外还有一个喜欢写博客的 AI 从业者,其博客值得我们学习与了解,就是 OpenAI 应用人工智能研究负责人 Lilian Weng,主要从事机器学习、深度学习和网络科学研究。她本科毕业于香港大学,硕士就读于北京大学信息系统与计算机科学系,之后前往印度安纳大学布鲁顿分校攻读博士。
她的 Blog:https://lilianweng.github.io/ 她的 Twitter:https://twitter.com/lilianweng
Reference
- https://beta.openai.com/docs/models
- https://karpathy.medium.com/software-2-0-a64152b37c35
- https://hub.baai.ac.cn/view/21726
- https://www.reddit.com/r/OpenAI/comments/zdrnsf/comment/iz3kfui/?context=3
- https://www.sohu.com/a/615541698_121255906
- http://blog.itpub.net/29829936/viewspace-2654536/
- http://tech.sina.com.cn/csj/2018-10-13/doc-ihmhafir3634167.shtml
- https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb#scrollTo=DefMidasFns
- https://en.wikipedia.org/wiki/BERT_(language_model)
- https://www.mikecaptain.com/2022/12/17/ai-bert-1/