【编译】Google 发布大型语言模型 BERT
- 原文:https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html
- 作者:Google AI Language 团队
- 编译:AI & 麦克船长
自然语言处理(Natural Language Processing,NLP)研究领域的最大挑战是缺乏训练数据。因为 NLP 是一个有很多完全不同任务的多样化领域,大多数针对特定任务的数据集仅仅包含几千到几十万人类标注的训练示例。但是,基于深度学习的现代 NLP 模型看到了用海量数据训练带来的显著好处,甚至达到 Million、Billion 级别的标注数据样本量。为了填补这个空白,希望能够在无标注的海量网络文本数据上进行通用语言模型的训练,研究人员开发了各种各样的技术,通常被称为预训练。
然后预训练模型在类似问答和情感分析的小数据集 NLP 任务上进行微调。与从头开始训练这些数据集相比,可以显着提高准确性。
这周,我们开源了一个 NLP 预训练的新技术,我们把它叫 BERT,即 Bidirectional Encoder Representation from Transformers。有了这次发布,这个世界上的任何人,都可以在一个云 TPU 上花 30 分钟,或者在一个 GPU 上花几个小时,训练一个 SOTA 的问答系统(或者各种各样的其他模型)。这次发布包括在 TensorFlow 上构建 BERT 的开源代码,以及多个预训练好参数的模型。在我们相应的论文中,我们在 11 个 NLP 任务上验证了 SOTA 的结果,包括非常挑战的 Stanford 问答数据集(SQuAD v1.1)。
1、是什么让 BERT 与众不同?
BERT 以最近在预训练上下文表示方面的工作为基础——包括半监督序列学习、生成式预训练、ELMo 和 ULMFit。然而,与之前的这些模型不同,BERT 是第一个深度双向、无监督的语言表示,仅使用纯文本语料库(在本例中为维基百科)进行预训练。
为什么这很重要?预训练的表示可以是上下文无关的或上下文的,上下文表示可以进一步是单向的或双向的。上下文无关的模型(比如 word2vec、GloVe)为每一个词汇表中的单词,生成一个词嵌入表示。例如,单词「bank」对于「bank account」和「bank of the river」有相同的上下文无关词表示。而上下文模型则会针对这两个桔子分别生成这个词的嵌入表示。例如对于句子「I accessed the bank account」,单向上下文模型将根据「I accessed the」来表示「bank」,但是 BERT 会用「I accessed the」和「account」来表示「bank」,从深度神经网络的底层双向生成。
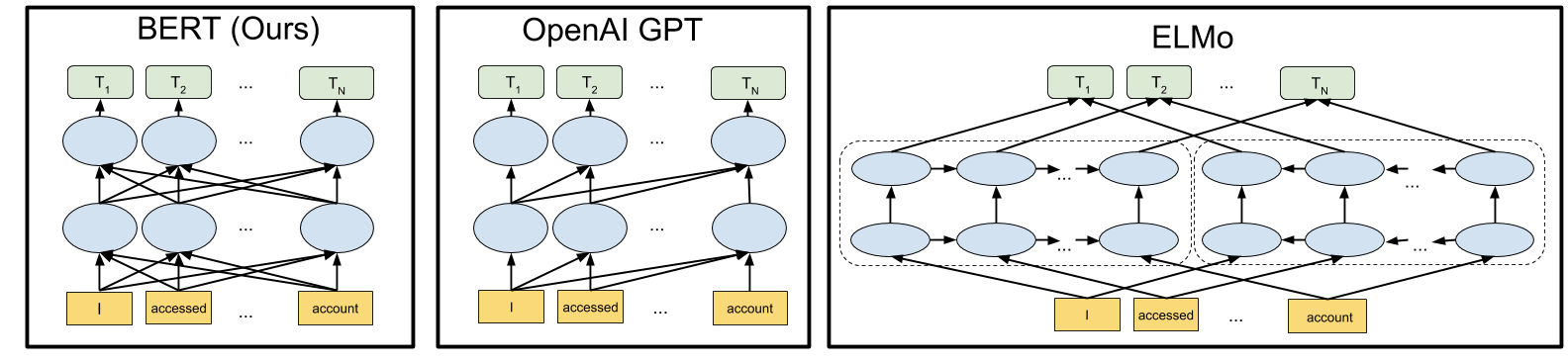
下图可视化地对比了 BERT 和同样达到 SOTA 的 OpenAI GPT、ELMo。箭头表示从一层到另一层的信息传输流,顶部的绿色方块表明了每个输入的最终上下文表示。
BERT 是深度双向的,OpenAI GPT 是单向的,ELMo 是浅度双向的。
2、双向的力量
如果双向这么强大,为什么之前没有?要理解为什么,考虑到单向语言模型是通过基于一个句子前面的词序列来预测下一个词的简单方式进行训练的。但是,我们不太可能用同样的方法简单地训练双向语言模型的,因为这样的话在一个多层模型中就会出现「See-Itself」问题。
为了解决这个问题,我们使用一种很直截了当的技术,就是对输入的词用掩码遮盖,然后用被遮盖的词的前后双向词序列来预测掩码词,例如:
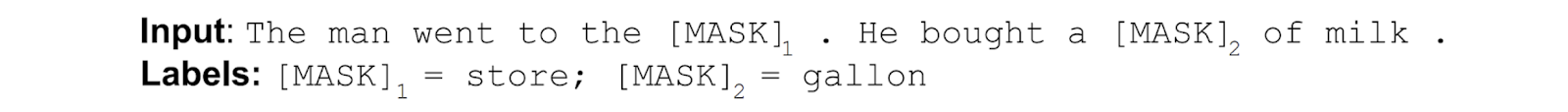
虽然这个想法已经存在很长时间了,但 BERT 是第一次成功地用于预训练深度神经网络。
BERT 还通过对「可以从任何文本语料库生成的、非常简单的任务进行预训练」来学习如何对句子关系进行建模:对于句子 A 和句子 B,B 是语料库中跟在 A 后面的句子,还是 B 只是随机的一个句子?比如:

3、用云 TPU 训练
到目前为止,我们所描述的一切似乎都相当简单,那么让它 work 的关键缺失部分是什么?云 TPU。云 TPU 然给我们能快速实验、debug、调整我们的模型,这对于让我们超越现有的预训练技术至关重要。由 Google 研究人员在 2017 年开发的 Transformer 模型架构给了我们让 BERT 成功的基石。Transformer 模型在我们的开源发布中有实现,tensor2tensor 库也有。
4、BERT 实验结果
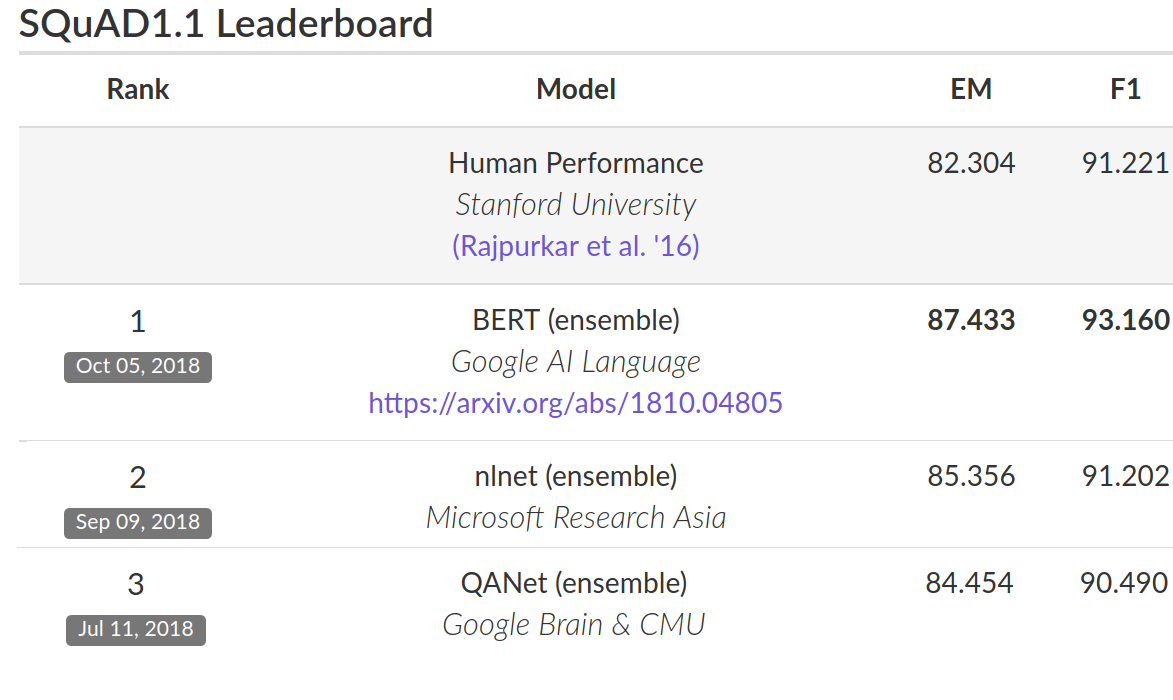
为了评估性能,我们吧 BERT 和其他 SOTA NLP 系统进行比较。重要的是,BERT 在几乎没有对神经网络架构进行特定于任务的更改的情况下完成了所有任务。在 SQuAD v1.1 任务上,BERT 取得了 93.2% F1 score (精确度的一种测量方法),超过了此前 SOTA 记录 91.6% 和人类水平的 91.2%:
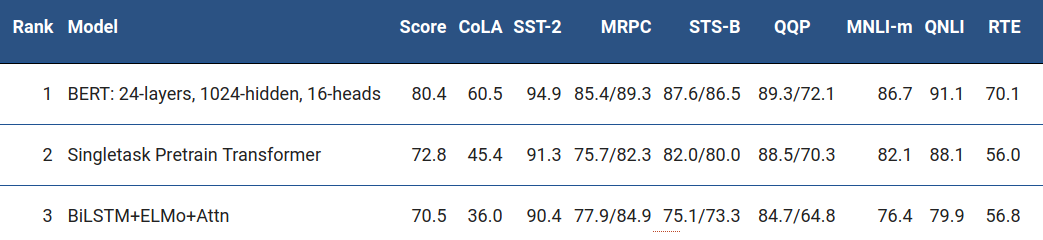
在非常挑战的、包括 9 种不同的自然语言理解任务(NLU)的 GLUE 测试上,BERT 把 SOTA 结果提升了 7.6%. 这些任务的标注数据量在 2,500 ~ 400,000 个样本之间。BERT 大大提升了性能表现:
5、让 BERT 为你工作
你可以用我们发布的模型,在非常广泛多样的 NLP 任务上进行数小时的微调就 OK 了。这次的开源发布也包括可以运行预训练过程的代码,尽管我们认为大多数使用 BERT 的 NLP 研究人员将永远不需要从头开始预训练他们自己的模型。今天我们发布的 BERT 模型是英文的,但是我们希望在接下来尽快发布支持多语种的预训练模型。
你开源在 http://goo.gl/language/bert 看到 TensorFlow 的开源实现和下载预训练好参数的模型的连接。或者,您可以通过 Colab 和《BERT FineTuning with Cloud TPUs》开始使用 BERT。
你也可以阅读我们的论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》获取更多细节。